记录了部分章节的笔记,这本书语言平时易懂,看得出来作者是很用心地写书,不是照着官方文档翻译,我推荐林子雨老师的这本书作为入门Spark的读物。
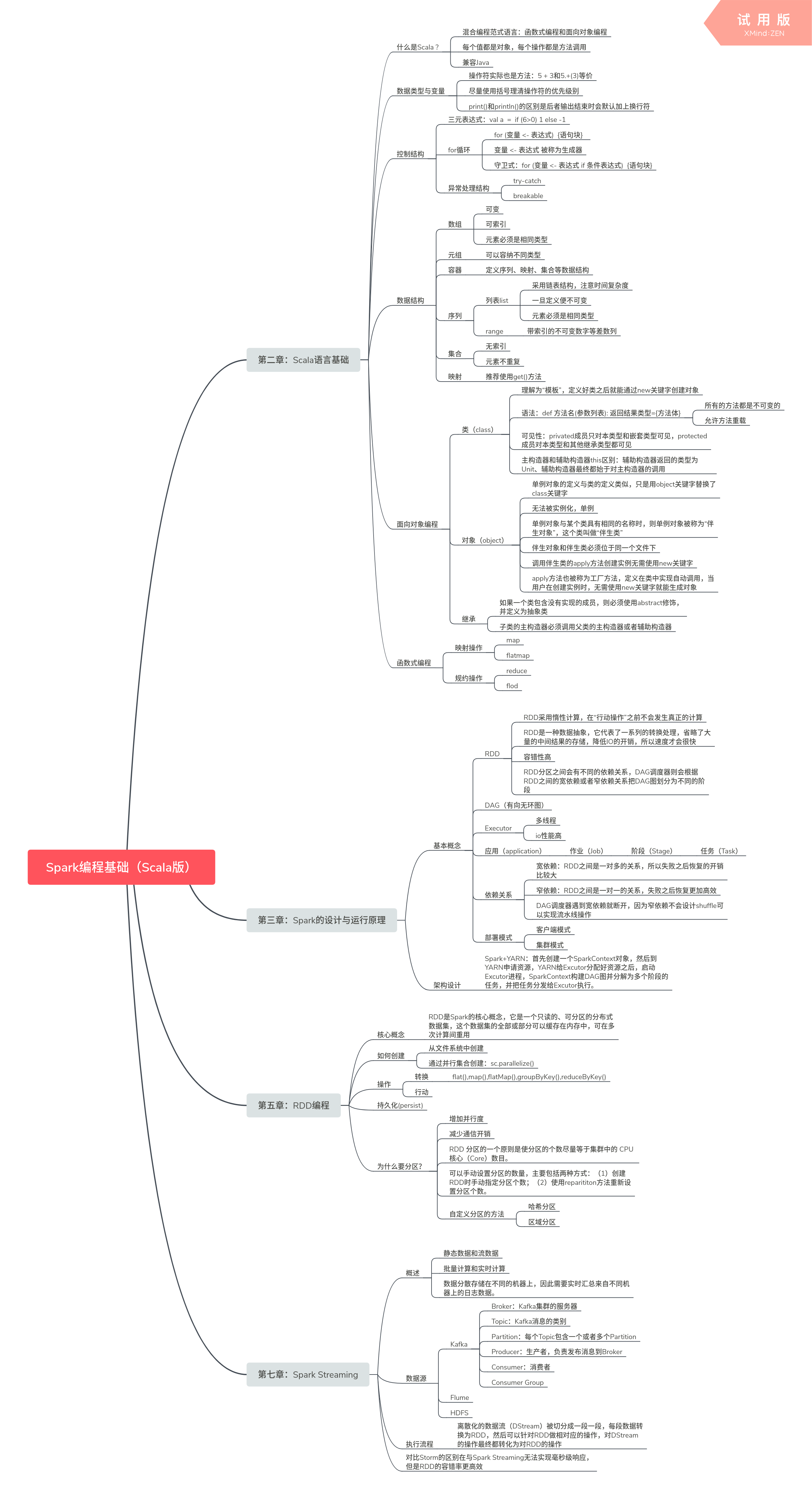
第二章:Scala语言基础
什么是Scala ?
- 混合编程范式语言:函数式编程和面向对象编程
- 每个值都是对象,每个操作都是方法调用
- 兼容Java
数据类型与变量
- 操作符实际也是方法:5 + 3和5.+(3)等价
- 尽量使用括号理清操作符的优先级别
- print()和println()的区别是后者输出结束时会默认加上换行符
控制结构
- 三元表达式:val a = if (6>0) 1 else -1
- for循环
- for (变量 <- 表达式) {语句块}
- 变量 <- 表达式 被称为生成器
- 守卫式:for (变量 <- 表达式 if 条件表达式) {语句块}
- 异常处理结构
- 数组
- 可变
- 可索引
- 元素必须是相同类型
- 元组
- 可以容纳不同类型
- 容器
- 定义序列、映射、集合等数据结构
- 序列
- 列表list
- 采用链表结构,注意时间复杂度
- 一旦定义便不可变
- 元素必须是相同类型
- range
- 带索引的不可变数字等差数列
- 列表list
- 集合
- 无索引
- 元素不重复
- 映射
- 类(class)
- 理解为“模板”,定义好类之后就能通过new关键字创建对象
- 语法:def 方法名(参数列表): 返回结果类型={方法体}
- 所有的方法都是不可变的
- 允许方法重载
- 可见性:privated成员只对本类型和嵌套类型可见,protected成员对本类型和其他继承类型都可见
- 主构造器和辅助构造器this区别:辅助构造器返回的类型为Unit、辅助构造器最终都始于对主构造器的调用
- 对象(object)
- 单例对象的定义与类的定义类似,只是用object关键字替换了class关键字
- 无法被实例化,单例
- 单例对象与某个类具有相同的名称时,则单例对象被称为“伴生对象”,这个类叫做“伴生类”
- 伴生对象和伴生类必须位于同一个文件下
- 调用伴生类的apply方法创建实例无需使用new关键字
- apply方法也被称为工厂方法,定义在类中实现自动调用,当用户在创建实例时,无需使用new关键字就能生成对象
- 继承
- 映射操作
- map
- flatmap
- 规约操作
- RDD
- RDD采用惰性计算,在“行动操作”之前不会发生真正的计算
- RDD是一种数据抽象,它代表了一系列的转换处理,省略了大量的中间结果的存储,降低IO的开销,所以速度才会很快
- 容错性高
- RDD分区之间会有不同的依赖关系,DAG调度器则会根据RDD之间的宽依赖或者窄依赖关系把DAG图划分为不同的阶段
- DAG(有向无环图)
- Executor
- 多线程
- io性能高
- 应用(application)
- 作业(Job)
- 阶段(Stage)
- 任务(Task)
- 阶段(Stage)
- 作业(Job)
- 依赖关系
- 宽依赖:RDD之间是一对多的关系,所以失败之后恢复的开销比较大
- 窄依赖:RDD之间是一对一的关系,失败之后恢复更加高效
- DAG调度器遇到宽依赖就断开,因为窄依赖不会设计shuffle可以实现流水线操作
- 部署模式
- Spark+YARN:首先创建一个SparkContext对象,然后到YARN申请资源,YARN给Excutor分配好资源之后,启动Excutor进程,SparkContext构建DAG图并分解为多个阶段的任务,并把任务分发给Excutor执行。
第五章:RDD编程
核心概念
- RDD是Spark的核心概念,它是一个只读的、可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,可在多次计算间重用
如何创建
- 从文件系统中创建
- 通过并行集合创建:sc.parallelize()
操作
- 转换
- flat(),map(),flatMap(),groupByKey(),reduceByKey()
- 行动
持久化(persist)
为什么要分区?
- 增加并行度
- 减少通信开销
- RDD 分区的一个原则是使分区的个数尽量等于集群中的 CPU 核心(Core)数目。
- 可以手动设置分区的数量,主要包括两种方式:(1)创建RDD时手动指定分区个数;(2)使用reparititon方法重新设置分区个数。
- 自定分区的方法
- 静态数据和流数据
- 批量计算和实时计算
- 数据分散存储在不同的机器上,因此需要实时汇总来自不同机器上的日志数据。
数据源
- Kafka
- Broker:Kafka集群的服务器
- Topic:Kafka消息的类别
- Partition:每个Topic包含一个或者多个Partition
- Producer:生产者,负责发布消息到Broker
- Consumer:消费者
- Consumer Group
- Flume
- HDFS
执行流程
- 离散化的数据流(DStream)被切分成一段一段,每段数据转换为RDD,然后可以针对RDD做相对应的操作,对DStream的操作最终都转化为对RDD的操作
对比Storm的区别在与Spark Streaming无法实现毫秒级响应,但是RDD的容错率更高效
思维导图