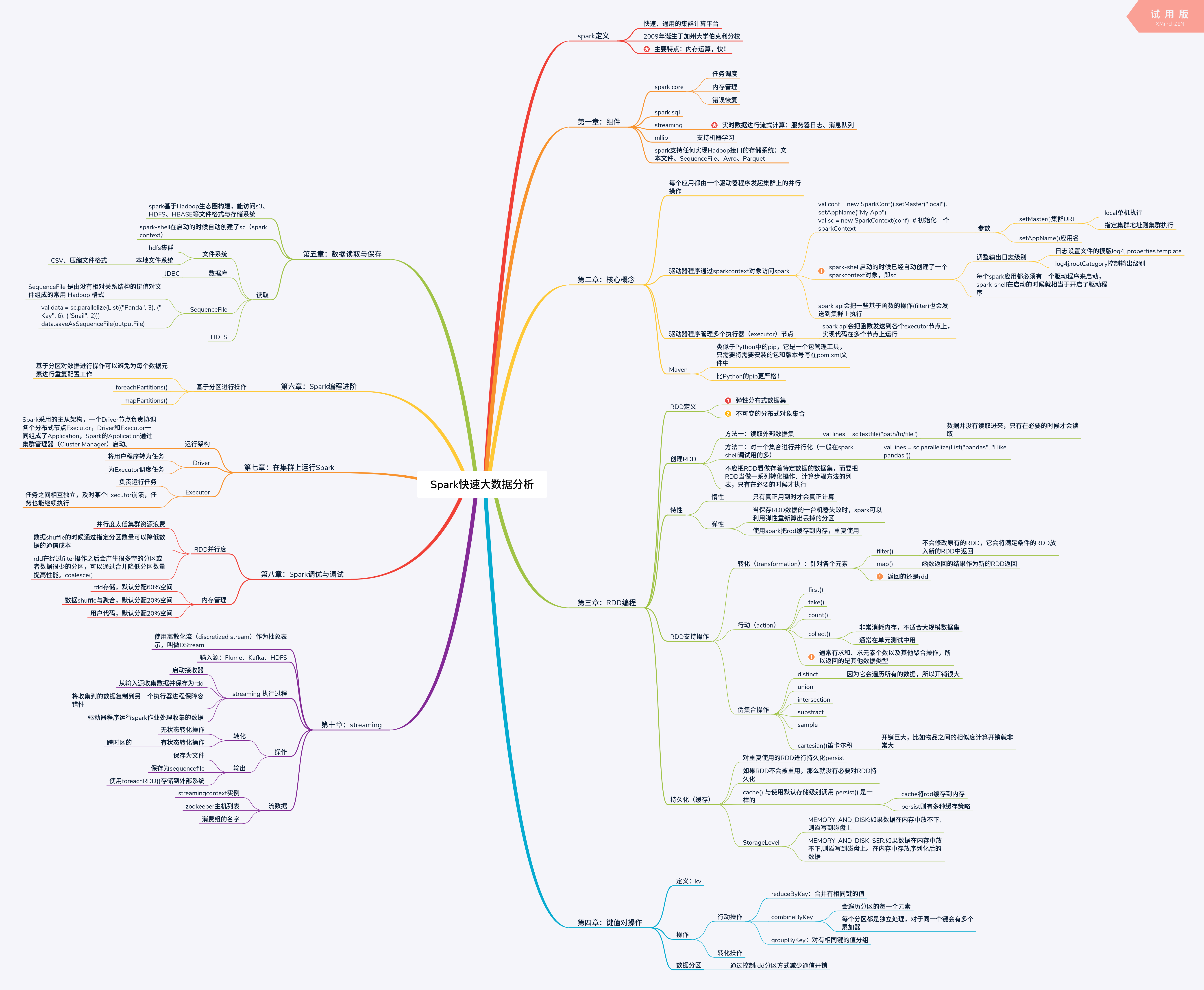
《Spark快速大数据分析》思维导图及笔记
spark定义
快速、通用的集群计算平台
2009年诞生于加州大学伯克利分校
主要特点:内存运算,快!
第一章:组件
spark core
- 任务调度
- 内存管理
- 错误恢复
spark sql
streaming
- 实时数据进行流式计算:服务器日志、消息队列
mllib
- 支持机器学习
spark支持任何实现Hadoop接口的存储系统:文本文件、SequenceFile、Avro、Parquet
第二章:核心概念
每个应用都由一个驱动器程序发起集群上的并行操作
驱动器程序通过sparkcontext对象访问spark
- val conf = new SparkConf().setMaster(“local”).setAppName(“My App”)
val sc = new SparkContext(conf) # 初始化一个sparkContext- 参数
- setMaster()集群URL
- local单机执行
- 指定集群地址则集群执行
- setAppName()应用名
- setMaster()集群URL
- 参数
- spark-shell启动的时候已经自动创建了一个sparkcontext对象,即sc
- 调整输出日志级别
- 日志设置文件的模版log4j.properties.template
- log4j.rootCategory控制输出级别
- 每个spark应用都必须有一个驱动程序来启动,spark-shell在启动的时候就相当于开启了驱动程序
- 调整输出日志级别
- spark api会把一些基于函数的操作(filter)也会发送到集群上执行
驱动器程序管理多个执行器(executor)节点
- spark api会把函数发送到各个executor节点上,实现代码在多个节点上运行
Maven
- 类似于Python中的pip,它是一个包管理工具,只需要将需要安装的包和版本号写在pom.xml文件中
- 比Python的pip更严格!
第三章:RDD编程
RDD定义
- 弹性分布式数据集
- 不可变的分布式对象集合
创建RDD
- 方法一:读取外部数据集
- val lines = sc.textfile(“path/to/file”)
- 数据并没有读取进来,只有在必要的时候才会读取
- val lines = sc.textfile(“path/to/file”)
- 方法二:对一个集合进行并行化(一般在spark shell调试用的多)
- val lines = sc.parallelize(List(“pandas”, “i like pandas”))
- 不应把RDD看做存着特定数据的数据集,而要把RDD当做一系列转化操作、计算步骤方法的列表,只有在必要的时候才执行
特性
- 惰性
- 只有真正用到时才会真正计算
- 弹性
- 转化(transformation):针对各个元素
- filter()
- 不会修改原有的RDD,它会将满足条件的RDD放入新的RDD中返回
- map()
- 函数返回的结果作为新的RDD返回
- 返回的还是rdd
- filter()
- 行动(action)
- first()
- take()
- count()
- collect()
- 非常消耗内存,不适合大规模数据集
- 通常在单元测试中用
- 通常有求和、求元素个数以及其他聚合操作,所以返回的是其他数据类型
- 伪集合操作
- 对重复使用的RDD进行持久化persist
- 如果RDD不会被重用,那么就没有必要对RDD持久化
- cache() 与使用默认存储级别调用 persist() 是一样的
- cache将rdd缓存到内存
- persist则有多种缓存策略
- StorageLevel
- 行动操作
- reduceByKey:合并有相同键的值
- combineByKey
- 会遍历分区的每一个元素
- 每个分区都是独立处理,对于同一个键会有多个累加器
- groupByKey:对有相同键的值分组
- 转化操作
数据分区
- 通过控制rdd分区方式减少通信开销
第五章:数据读取与保存
spark基于Hadoop生态圈构建,能访问s3、HDFS、HBASE等文件格式与存储系统
spark-shell在启动的时候自动创建了sc(spark context)
读取
- 文件系统
- hdfs集群
- 本地文件系统
- CSV、压缩文件格式
- 数据库
- JDBC
- SequenceFile
- SequenceFile 是由没有相对关系结构的键值对文件组成的常用 Hadoop 格式
- val data = sc.parallelize(List((“Panda”, 3), (“Kay”, 6), (“Snail”, 2)))
data.saveAsSequenceFile(outputFile)
- HDFS
第六章:Spark编程进阶
基于分区进行操作
- 基于分区对数据进行操作可以避免为每个数据元素进行重复配置工作
- foreachPartitions()
- mapPartitions()
第七章:在集群上运行Spark
运行架构
- Spark采用的主从架构,一个Driver节点负责协调各个分布式节点Executor,Driver和Executor一同组成了Application,Spark的Application通过集群管理器(Cluster Manager)启动。
Driver
- 将用户程序转为任务
- 为Executor调度任务
Executor
- 负责运行任务
- 任务之间相互独立,及时某个Executor崩溃,任务也能继续执行
第八章:Spark调优与调试
RDD并行度
- 并行度太低集群资源浪费
- 数据shuffle的时候通过指定分区数量可以降低数据的通信成本
- rdd在经过filter操作之后会产生很多空的分区或者数据很少的分区,可以通过合并降低分区数量提高性能。coalesce()
内存管理
- rdd存储,默认分配60%空间
- 数据shuffle与聚合,默认分配20%空间
- 用户代码,默认分配20%空间
第十章:streaming
使用离散化流(discretized stream)作为抽象表示,叫做DStream
输入源:Flume、Kafka、HDFS
streaming 执行过程
- 启动接收器
- 从输入源收集数据并保存为rdd
- 将收集到的数据复制到另一个执行器进程保障容错性
- 驱动器程序运行spark作业处理收集的数据
操作
- 转化
- 无状态转化操作
- 有状态转化操作
- 跨时区的
- 输出
- streamingcontext实例
- zookeeper主机列表
- 消费组的名字
思维导图