先前的一段时间接手到一个流失用户预测的活,也就是根据某个群体用户的行为数据(动态特征)、自身特征(静态特征),建立一套流失预警的分类模型,预测用户的流失概率。类似于这种机器学习任务,毫无疑问,逻辑回归算法是首选之选。因为在很多场景下的需求问题都可以很容易地转化为一个分类或者预测问题,而逻辑回归的输出值可以无缝地适应这两类问题,如果你想要做分类,那么你控制好门槛值(threshold),如果你想做预测,它输出的概率值很好解释。所以,逻辑回归这个算法在机器学习中有点AK-47的味道:简单易懂、适应场景广泛、容易优化,如果效果不好,尝试增大数据集、增加几个特征、调节参数这些常见优化方法,一般来说,应对离线场景下的需求绰绰有余。这篇文章暂时就离线问题作为讨论的话题,因为我还没有特别熟练的实时机器学习模型部署经验。
对比Python引用Scikit-Learn构建机器学习模型和使用Scala在Spark下搭建机器学习模型,两者也有值得注意的地方,比如Spark在训练的时候更加直观,你只需要把所有的特征全部汇集到features一列下就行,然后再指定一列作为label,到此为止就算是成功了一半。
样本选择
样本的选择是模型搭建中很关键的一个环节,因为它直接会关系到你的模型的预测对象是否符合需求,比如这篇文章介绍就比较详细:用户增长分析——用户流失预警 - 云+社区 - 腾讯云。举个例子,如果你要预测平台忠实用户的流失概率,那么你首先要考虑的问题便是如何定义忠实的活跃用户,只有先从用户池划定了一个区域,然后所有的分析、特征选取、训练预测都围绕圈定的用户群体来做,否则你的模型做得再好也是徒劳的。我是从以下几个方面来定义活跃用户的:
- 过去N天登录次数大于M次
- 连续活跃的天数大于N次
- 用户的主要功能事件行为
- 过滤黑名单用户、新增用户、作弊用户
- ……
当然,过滤的条件越多,你的SQL也会越来越复杂,你可能需要把SQL层层嵌套,这个环节需要非常细心。
特征提取
做完了上述的工作之后,下一步我们需要做的就是如何选取特征了,这也是相当关键的一个步骤(貌似没有不关键的==),garbage in garbage out,选取特征的好坏直接决定了模型的质量。你需要根据你所在的业务场景设计自己的指标体系,我所在项目是娱乐社交平台,关系用户留存的因素我总结为三大类:社交行为、业务行为和消费行为,下图展示的是我在模型中选取的部分特征,其中第一个部分的业务、社交活跃特征最多,总共有40个,这些特征的计算工作依赖前期数据项目人天表的积累,如果之前的这些数据项目没有做好,临时再去计算这些特征需要花费大量的精力;第二和第三个部分的业务行为特征我主要涉及到用户的消费行为,很容易想到一个在平台经常消费送礼的用户应该是不大可能会流失的,而那些消费行为记录为零的用户则很有可能再也不玩APP了;截图中还有一部分特征没有显示出来,这部分的特征我主要选的是用户的一些反馈行为,比如说举报其他用户或使用APP过程中的反馈行为,这些行为数据跟用户的流失存在着很大的关系。总的来说,特征的选取需要贴合实际的业务场景,先理解了业务场景剩下的工作便是“开脑洞”从各个业务表中寻找特征数据。
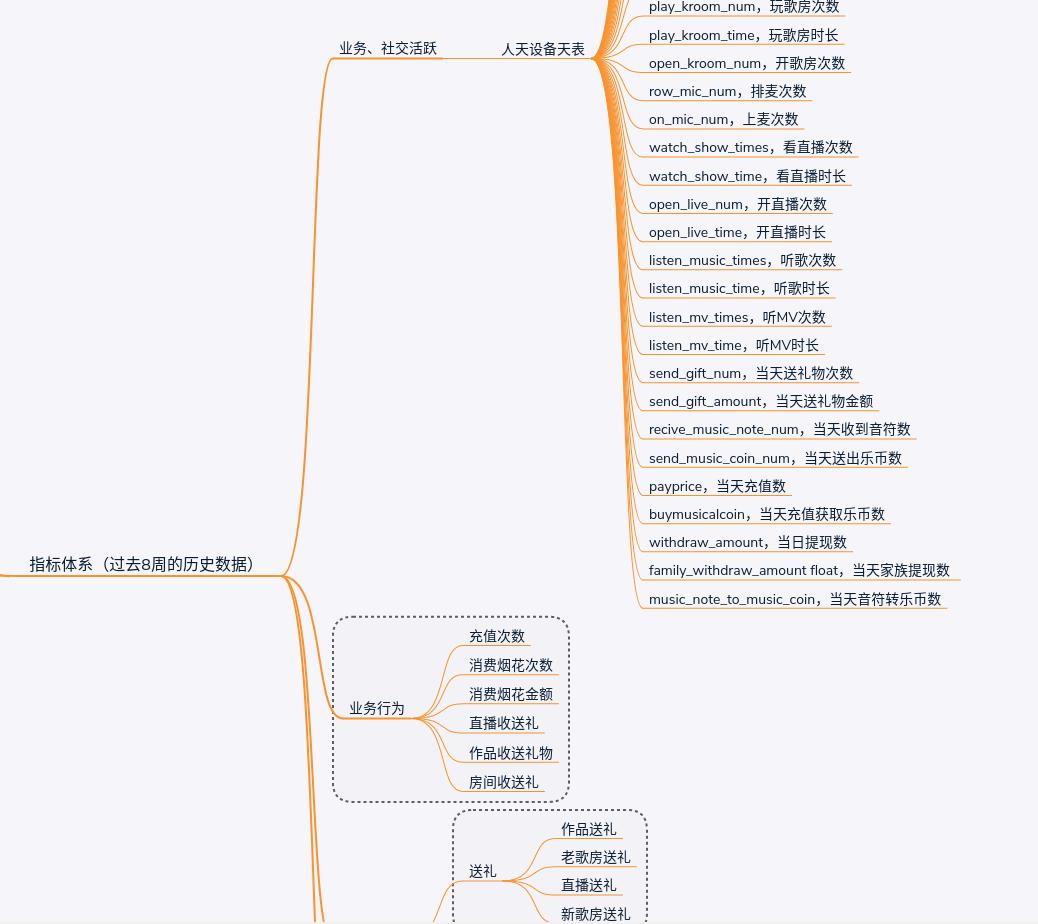
在正式进入模型的搭建之前,我们最好在心底确定下一个目标,确保喂给训练器的dataframe是一个用户id对应一行特征数据,并且数据还需要符合没有null值和空值、连续型的特征字段取值是double的条件。
模型搭建与训练
为了方便阅读代码,我把模型训练部分的代码全部放在文章的末尾了。
另外还遇到的一个问题是性能,当时我总是遇到内存溢出,后来我发现自己对于业务场景的理解有错误,也就是数据的准备不需要及时化,我的业务场景是离线的,所以我不需要像实时预测的需求那样拿到数据之后立马做出判断,所以这两步连接在一块的话就会造成OOM的错误,所以在离线的场景下,我们可以将离线的预测拆分为数据准备、训练、预测三个阶段,或者是根据你的需要分为更多的步骤,这样能减少内存占用的压力。
SparkML还有一个比较方便的就是它的pipeline,pipeline,顾名思义,即流水线。想象你的原始数据需要进行各种转换操作,代码会变得非常冗余难以阅读,在pipeline下,你至于要把需要的转换操作放在pipeline里面即可,1
2val pipeline = new Pipeline()
.setStages(Array(assembler,stdScaler,featureSelector,labelIndexer,lr))
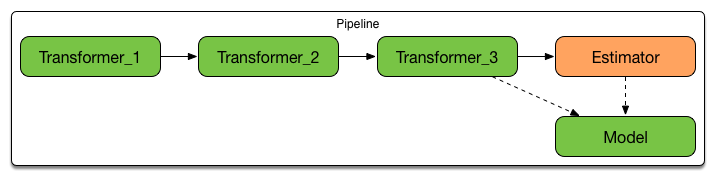
比如assembler是把所有的特征数值和向量全部汇总到一列下,stdScaler是对特征数据做标准化处理,featureSelector是特征选择器,labelIndexer则是目标变量转换操作,这样就保证了数据和数据操作的代码不会混合到一块,可以说pipeline真的让数据模型的代码变得很整洁!
网格搜索
为了让模型能够训练出一组更好的参数,网格搜索是必不可少的,在Spark中我们可以通过ParamGridBuilder来构建一个参数网格搜索器。在本文中我选择了特征数量、正则化系数、elasticNetParam三个参数作为优化的对象:
- 特征数量:虽然在模型中引入了很多的特征,但不是每一个特征都起作用,那些作用不大的特征反而会拖慢运行的速度,所以你可以根据实际的情况设置一组特征数量,比如(10,20,30)就是分别从所有特征中挑出10个、20个、30个最有代表性的
- 正则化系数:默认是0.0(一般业务场景下数据都比较稀疏,所以正则化系数要尽量取小一点,如0.01,0.001)
elasticNetParam:是混合了L1和L2正则化系数的参数,公式如下:$\alpha \left( \lambda |w|_1 \right) + (1-\alpha) \left( \frac{\lambda}{2}|w|_2^2 \right) , \alpha \in [0, 1], \lambda \geq 0$,elasticNetParam指的就是公式中的$\alpha$,它代表了L1和L2正则化之间的权衡,当elasticNetParam越接近于1时,L1正则化发挥的作用就越大,这时就会导致特征的权重很多为零,当elasticNetParam越接近于0,L2发挥的作用就越大,会导致特征的权重变得很小。Spark官方文档解释:Set the ElasticNet mixing parameter. For alpha = 0, the penalty is an L2 penalty. For alpha = 1, it is an L1 penalty. For alpha in (0,1), the penalty is a combination of L1 and L2. Default is 0.0 which is an L2 penalty.
交叉验证
除了正则化手段,机器学习中还可以通过交叉验证来防止模型的过拟合,Spark提供了CrossValidator接口用于将训练和测试集数据切分为K折,比如5折交叉验证,CrossValidator会生成5组(训练集,测试集)数据,4/5用于训练,1/5用于验证,然后CrossValidator会根据5个模型计算得到的一个平均评估指标(average evaluation metric)。值得注意的是,交叉验证是非常耗费时间的,比如网格搜索中有两个参数,一共4×2种组合,再加上K折交叉验证,那么就是4×2×k种模型的组合了。
测试模型
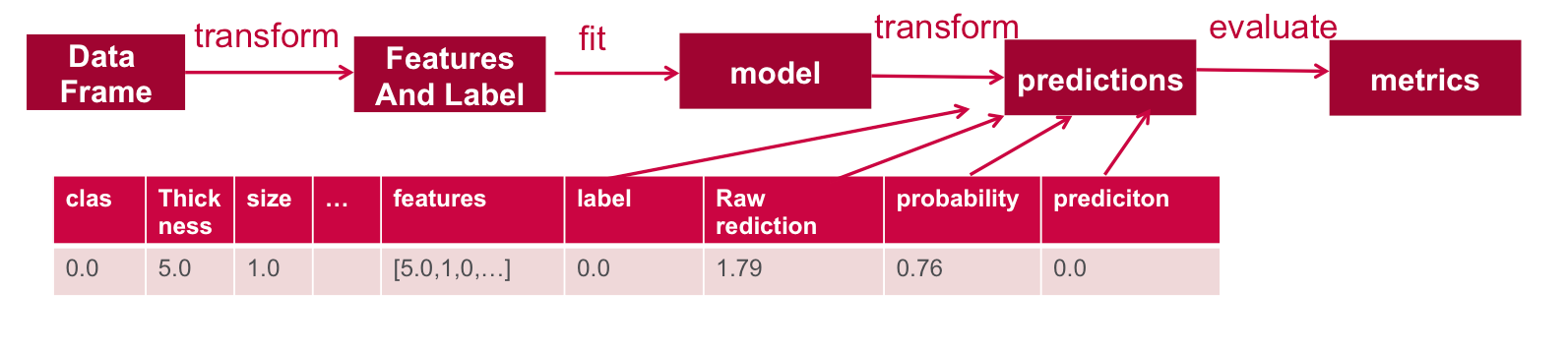
模型训练完了之后紧接着我们就需要在测试数据集上测试模型,Spark测试模型的步骤如下,用已有的model去transform测试数据集,然后数据集中会新生成rawPrediction、probablity、prediction三列,分别代表原始预测、概率值、预测结果。比如1.79是原始预测值,经过sigmoid转换之后变成了[0,1]之间的概率值,再根据你自己定义的门槛值来确定预测结果是正或反。通常,测试逻辑回归模型的指标有auc,在Spark中可以用BinaryClasssificationEvaluator获得auc的值。
分类任务除了auc指标,还需要考察查准率和召回率,关于这些指标的解释可以参考我的先前的文章:评估机器学习模型:指标解释 | Thinking Realm。而查准率和召回率则需要根据具体业务场景,比如在本文模型的目标是找到那些流失的用户,所以我更关注的是流失用户的查全率,即模型能把实际数据中的流失用户找出来,而总体的准确率能够达到合格的水平就够了。
1 | object UserLossPredictionDriver { |
在构建模型中遇到的问题
正负样本分配权重
样本分布不均匀是再正常不过的了,计算正负样本占比,给不平衡的样本分配更多的权重。
machine learning - Dealing with unbalanced datasets in Spark MLlib - Stack Overflow
模型所有系数都为零
Empty Coefficients in Logistic regression in spark - Stack Overflow
python - all coefficients turn zero in Logistic regression using scikit learn - Stack Overflow
如何打印模型特征的权重?
Matching LR Coefficients With Feature Names - Databricks
如何提取交叉验证模型最佳参数?
scala - How to extract best parameters from a CrossValidatorModel - Stack Overflow
逻辑回归多分类问题
多分类实现方式介绍和在 Spark 上实现多分类逻辑回归 | 码农网
如何在SQL中将所有特征放置在一行?
Pivot rows to columns in Hive - Analyticshut

