前一段时间在工作中发现自己对于统计知识的理解有点不够系统,比如我知道了解数据的形态需要从集中趋势、离散趋势以及形态方面着手,但是对于其中的细节却总是模糊的,比如我无法回答为什么通常用标准差而不是方差来反映数据的离散程度,我也无法回答泊松分布到底是个什么鬼,所以出于非应试的目的,利用差不多一个多月的业余时间,我把贾俊平编写的统计学的前半部分大致的过了一遍,从中选出几点我先前不太明白的地方记录下来,先记录这么多,以后有新的再补上。
参数与统计量
参数与统计量的区别:参数是对总体特征的概括性数字度量,因为总体数据通常是不知道的,所以参数一般未知。统计量是描述样本数据的概括性数字度量,因为样本是抽样出来的,所以统计量是已知的,统计量用于估计总体的参数。
数据描述
我们一般可以将数据大致分为:数值型、分类型和顺序型数据,顺序型数据就是将数值型数据按照大小排序后的形态,一般从集中趋势、离散趋势和形态度量这三个方面去获得对数据的整体感知。在复习统计学的时候我发现我先前对于数据离散趋势的度量并不是那么准确,比如,对于分类数据来说,有异众比率,顺序数据来说,是四分位差,数值型数据主要是方差和标准差。
其中有一条经验法则挺值得注意的,也就是说在数据对称分布的时候,大多数的数据是在±k个标准差的范围之内,如果某个数据超过了这个范围,那可以把它被认定是离群点。对于不对称分布的数据,则可以根据切比雪夫不等式来知道大多数数据的分布范围。
当我们想要比较两组数据的离散程度,如果均值不同的话是不能直接拿标准差去比较的,因为他们不在同一个量纲下,所以为了消除量纲的差距,我们需要用相对离散程度,即离散系数,标准差与平均数之比

均值与数学期望的区别
均值是实验后对统计结果的平均数而数学期望是实验前根据概率分布对实验结果的预测的平均值。因为我们在实验中没办法穷尽所有的可能,所以只能根据概率,分布去预测样本的平均值,即数学期望。
统计量及其抽样分布
抽样分布、参数估计和假设检验是统计推断的三个中心内容,在正态分布的总体条件下,统计学下有三大分布:卡方分布、t分布和F分布。这三大分布对后面的参数估计和假设检验至关重要。
还需要记得一条伟大的中心极限定理。中心极限定理的大致意思就是如果我从一个服从正态分布的总体中抽出n个样本,当样本量充分大的时候(经验上一般大于30即可)样本的均值也是服从正态分布。
之前一直不理解泊松分布和指数分布在实际中的应用是如何的,直到看到了阮一峰写得这篇简短明了的文章才恍然大悟。
泊松分布是单位时间内独立事件发生次数的概率分布,指数分布是独立事件的时间间隔的概率分布。
参数检验
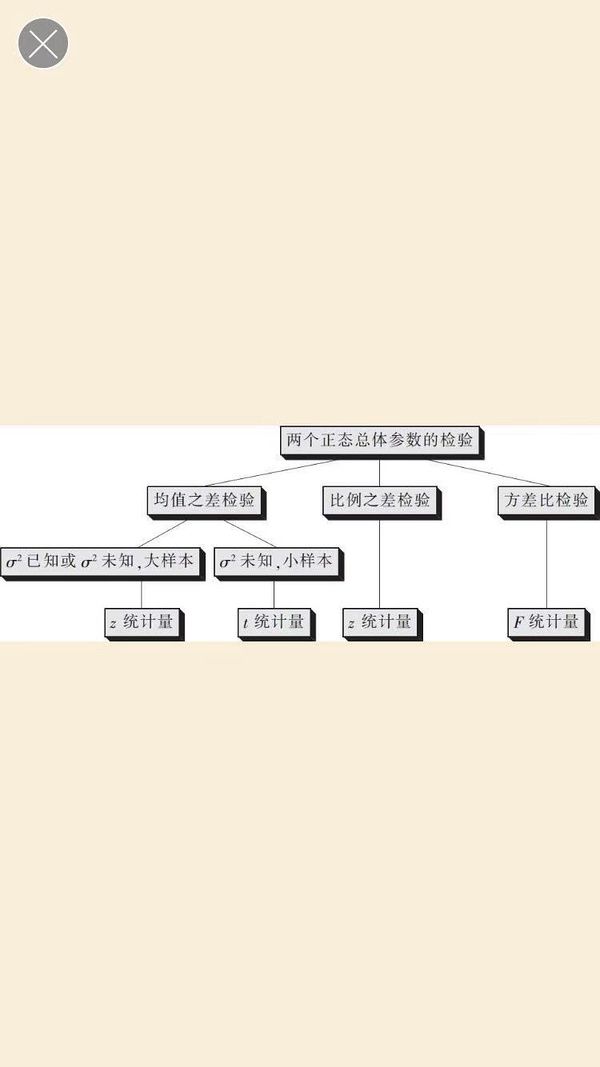
比较两个群体之间的参数是否有显著差别,比如两个不同行业职工的平均收入水平是否存在差异,一般的逻辑是直接比较均值或者更不合理的是拿一个群体的均值作为代表跟另外一个群体相比较,而从统计学的意义上来说,需要用两个总体参数的检验寻找答案,按照下图属于两个总体参数之差的检验,那么根据样本大小或者方差是否位置分别采用z统计量和t统计量来做检验。