在浅析 Spark Architecture:Shuffle(一) | Thinking Realm这篇文章中我主要向大家介绍了Spark Shuffle的运行原理和随着Spark升级导致Shuffle运行机制的变化。
而这篇文章主要介绍在Spark中哪些操作会触发Shuffle、Shuffle的bypassMergeThreshold运行机制和4个与Shuffle相关的参数。
何时会触发Spark Shuffle操作?
首先,从字面上来理解,Shuffle的意思就是“洗牌”,就是要把原来混乱的数据重新整理,而往往数据又不是分布在同一个地方的,在这个过程中必然会涉及到数据的移动,所以不难理解Shuffle是一个非常消耗资源的操作,通常可以通过数据分区来降低Shuffle带来的网络传输开销。
在Spark中,map、filter、union操作不会触发Shuffle操作,因为这些操作都是针对单个数据本身的改变,数据与数据之间并不会发生关联或者交换操作。而诸如分区操作如repartition 、coalesce或者groupByKey、sortByKey等ByKey的操作一般会触发Shuffle,groupByKey会对数据做分组处理,而sortByKey需要比较数据与数据之间的先后顺序。
| 类型 | |
|---|---|
| repartition | repartitionorcoalesce |
| ByKey | groupByKeyorsortByKey |
| join |
推荐两个链接:第一个说的是partitionBy和repartition之间的区别,第二个解释在Spark中哪些操作会引发Shuffle。
Spark shuffle – Case #1 – partitionBy and repartition – Tantus Data
mapreduce - When does shuffling occur in Apache Spark? - Stack Overflow
Spark(>1.2.0)Shuffle的bypassMergeThreshold运行机制
从Spark 1.2.0开始,Spark Shuffle默认的算法便变为了sort,可以通过spark.shuffle.manager选择相应的Shuffle算法。在上一篇文章中有提到过,Sort Shuffle的原理与Hadoop Shuffle有着相似的实现逻辑,Map端只会输出两个文件,分别是数据文件和记录结果数据的索引文件,由此,Reduce端就很容易根据索引文件找到记录结果的数据文件位置。
值得注意的是,最新版本的Spark在Sort Shuffle机制也并不完全只是Sort Based,在SortShuffleManager下有一个spark.shuffle.sort.bypassMergeThreshold参数比较有意思,它主要用于决定当Reduce端的任务不超过Threshold值的时候采用类似Hash Based的Shuffle机制,即直接将Map端的文件先分别写入单独的文件,但是它又跟Hash Based不完全相同,它在最后一步还是会将这些文件合并成为一个单独的文件。
举个例子比较好理解,如果说你要从A城市出发去B城市,现有两种选择:打车和坐火车,打车比较灵活适合中短距离,距离太远则不经济,火车价格低廉适合距离长距离。如果A城市和B城市之间的距离大约50公里以内,那么我建议你还是打车比较合理,毕竟打车比较灵活,可以决定自己的时间。而当距离超过100公里,那现在就有必要考虑坐火车了。
Hash Based Shuffle之于Sort Based Shuffle正如打车和 坐火车的关系,Hash Based适合数据量不是特别大的计算任务,此时它会比Sort Based更快;而数据量很大的情况下,Sort Based就更胜一筹,Hash Based会把大量的Map结果写入内存,会相当耗费资源,给GC造成了巨大的压力,得不偿失。下图描述了bypassMergeThreshold运行机制下SortShuffleManager选择类似Hash Based的Shuffle原理(图片来源:Spark性能优化指南——高级篇 - 美团技术团队)。
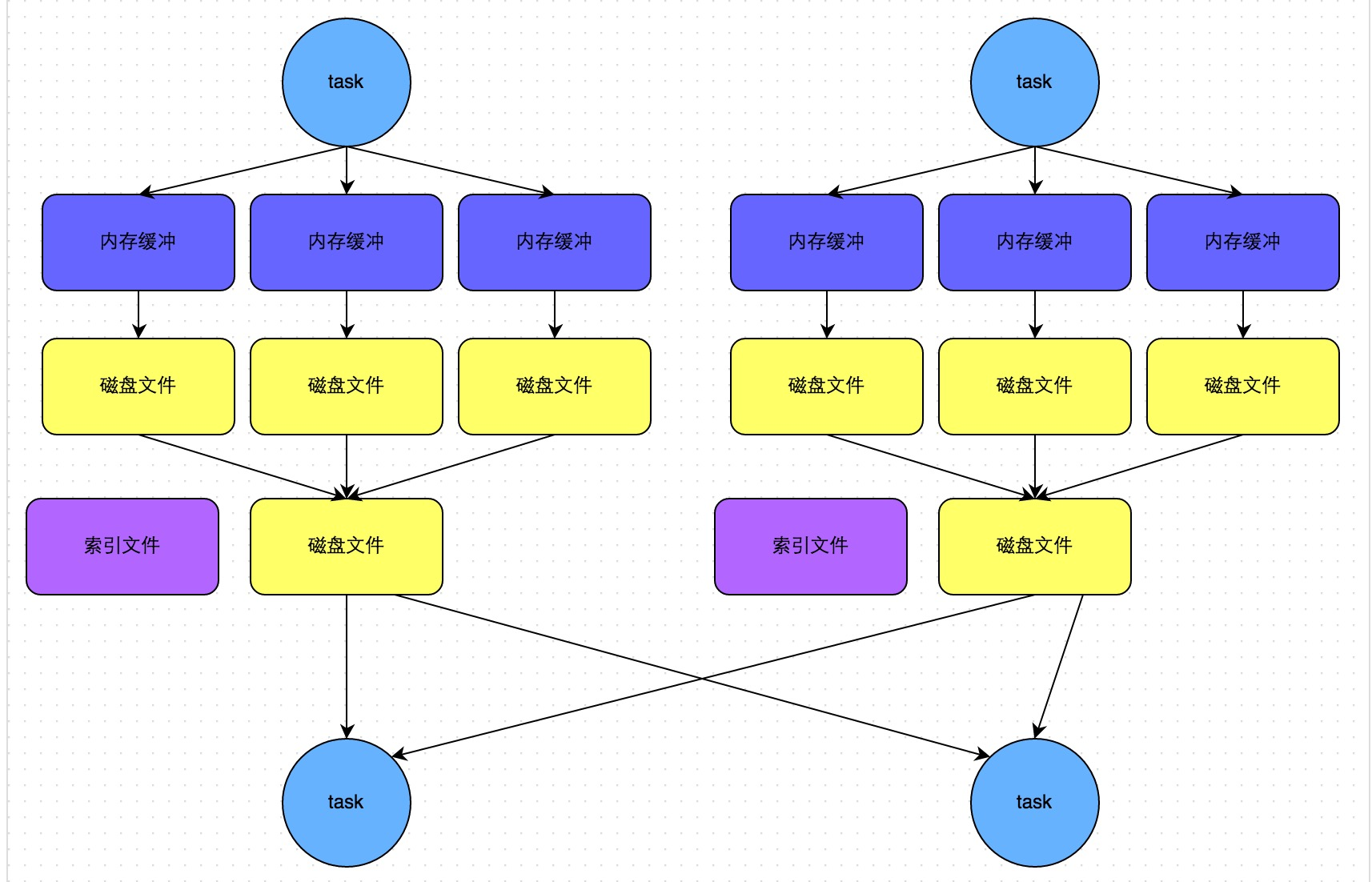
Spark Shuffle的spark.shuffle.sort.bypassMergeThreshold参数正是为了兼顾Hash Shuffle在小数据集上的优异表现而设置的,spark.shuffle.sort.bypassMergeThreshold参数默认为200,当Map端的任务数量小于200时,此时的Shuffle选择的是Hash Shuffle,也就是先将大量的中间数据文件写入内存并且不排序,只是在最后每个Map task都会把中间的数据文件再汇总为一个数据文件给Reducer,这样一来大大提高运行的效率。
所以,我这里给出的建议是,如果集群的GC压力比较大,并且处理的是需要进行排序的Shuffle操作比如sortBy,可以适当地减小bypassMergeThreshold的值,选择Sort Based Shuffle。
与Spark Shuffle调优相关的参数
spark.shuffle.spill:溢写操作,默认打开,决定当内存不够用时将数据临时写入磁盘spark.shuffle.memoryFraction:决定了当Shuffle过程中使用的内存达到总内存多少比例的时候开始启动溢写(spill)操作,默认是0.2,也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。建议当内存不够用的时候可以适当地降低这个参数的值,可以避免出现OOMspark.storage.memoryFraction:用于设置RDD能在Executor内存中持久化能占的比例,默认是0.6,当代码中的持久化操作比较多时,可以适当提高该参数的值,反之,当GC频繁导致内存不够用的话,就需要降低该参数,将数据直接写入磁盘spark.shuffle.spill.compress / spark.shuffle.compress:决定是否对Spill的中间数据,最终的shuffle输出文件进行压缩操作,默认打开
在默认情况下,Spark 会使用 60%的空间来存储 RDD,20% 存储数据混洗操作产生的数据,剩下的 20% 留给用户程序。用户可以自行调节这些选项来追求更好的性能表现。如果用户代码中分配了大量的对象,那么降低 RDD 存储和数据混洗存储所占用的空间可以有效避免程序内存不足的情况。

