先前一篇文章基于 Tensorflow 的 TextCNN 在搜狗新闻数据的文本分类实践是CNN在文本分类中的一次尝试,在接触了LSTM之后了解到它自然语言处理中有非常广泛的应用,比如情感分析、信息提取(命名体识别)、机器翻译等领域大放异彩,本文就来看看它在文本分类上究竟会有什么样的表现。
因为原始数据的处理在上一次尝试中已经完成了,所以在本次实验中只需要完成RNN模型的参数配置和模型运行的脚本。
RNN配置参数
1 | class TRNNConfig(object): |
RNN训练与验证
RNN的训练验证部分代码与CNN的差别很小,修改模型存储路径等几个小地方即可。
1 | # coding: utf-8 |
模型训练和测试结果
从运行的结果来看,RNN的训练时间明显要长很多,大约是CNN的两倍,并且内存占用也明显要高。
GRU
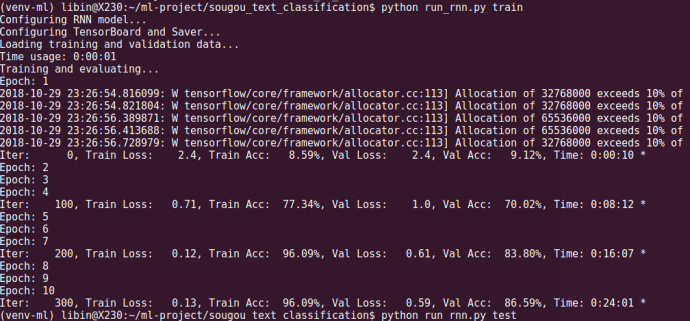
经过10轮的训练,模型在训练集上的准确率达到96.09%,验证集达到86.59%,相比CNN来说表现还是要差一点点,原因嘛,暂时也不知道(==)。因为训练数据集比较小,所以有的epoch训练结果没有打印在屏幕上。
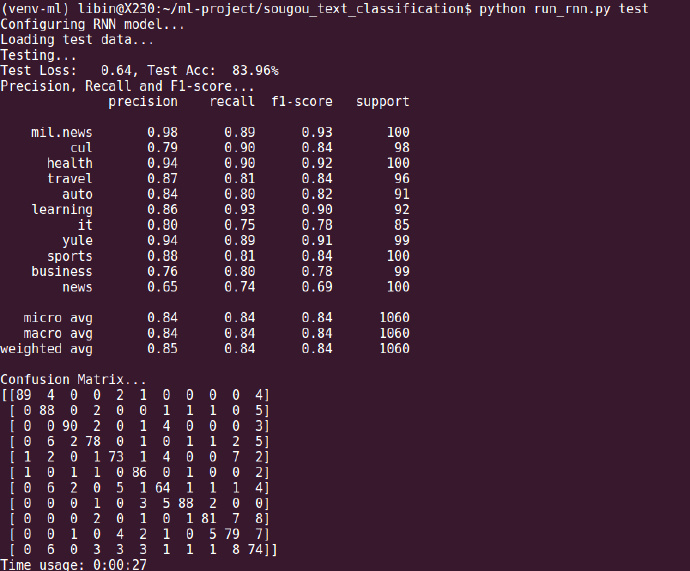
再看看测试集上的表现,总体准确率为83.96%,除了文化(cul)、商业和社会(news),其他类别的准确率都在80%以上。社会类别的新闻表现最差,才65%,但是我觉得跟搜狗的新闻数据质量也有关系,因为就文章内容来说,文不对题和内容属性模糊的频率很高,特别是社会类别,似乎分在文化类也可以。
LSTM
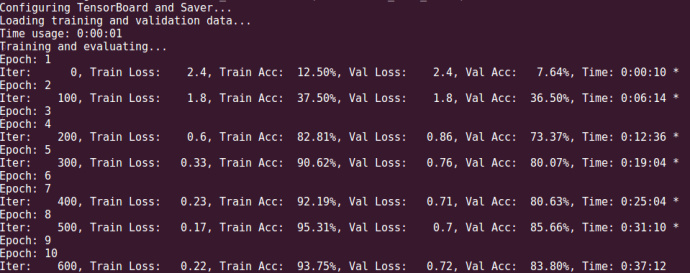
把RNN的cell换成LSTM,看看效果如何。训练的时间依然很长,花了半个小时,10个epoch中,在第8轮验证集数据达到最佳效果,最佳的训练集准确率为95.31%,验证集准确率为85.66%。
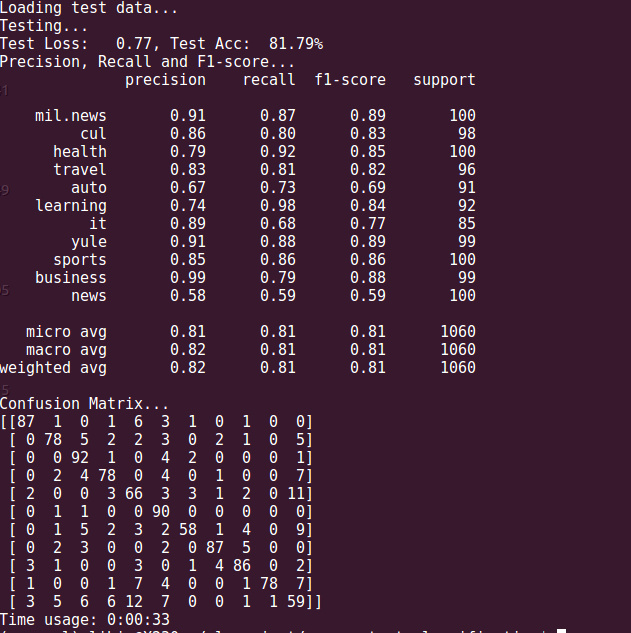
测试集数据,准确率为81.79%,这次轮到社会类和汽车的类别预测效果最差,需要进一步优化参数。
思考
RNN模型在文本分类任务上表现不佳的原因可能有:
- RNN训练本身需要大量的数据,而在本次实践中拿到的数据每个类别仅仅只有550条
- 本次新闻分类尚未引进预训练好的词向量,所以出现了过拟合
- 基于字符级的文本分类比基于词的表现要差?

