这篇文章记录了从零开始用 tensorflow 构建卷积神经网络模型,并对搜狗的新闻数据做的文本分类实践。众所周知,tensorflow 是一个开源的机器学习框架,它的出现大大降低了机器学习的门槛,即使你没有太多的数学知识,它也可以允许你用“搭积木”的方式快速实现一个神经网络,即使没有调节太多的参数,模型的表现一般还不错。目前,tensorflow 的安装已经变得非常简单,一个简单的pip install tensorflow即可,然后import tensorflow as tf就能愉快玩耍了。
1. 背景
卷积神经网络,即CNN,它的核心思想是捕捉数据的局部特征(感兴趣的同学可以阅读我先前写的一篇关于CNN的笔记:机器学习算法系列(13)理解卷积神经网络 | Thinking Realm),不仅仅在图像领域大放异彩,CNN在文本分类领域也有很强的表现。在Yoon Kim的这篇论文中,比较清楚地解释了CNN用于文本分类的原理,关键在于如何将文本向量化,如下图,即把每个词都表示为一个 1×k的向量,对长度为N的文本则表示为N×K的矩阵,经过这一步处理,那么我们就可以把图像上的分类经验应用到文本上来了。
现在有预训练好的中文词向量,但这不是本文的重点,因为这里不需要用到预训练好的词向量,本文的文本分类是基于字符级的CNN实现,也就是并没有对文本数据做分词处理,而是从原始文本中建立词汇表,然后把文本中的每个字符都对应编码。比如,“我爱北京天安门。”,我们就会把这段文本全部打散成为“我”、“爱”、“北”、“京”、“天”、“安”、“门”、“。”,甚至标点符号、特殊字符都会有对应的编码,一开始还有怀疑,不过从模型的表现来看,真香。
本文用到的数据集来自搜狗实验室(Sogou Labs)提供的新闻数据,涵盖了国内,国际,体育,社会,娱乐等18个频道的新闻数据,不过数据集的质量不是特别高,存在大量的分类不清晰、文不对题数据。限于单机的性能,又没有 GPU,所以我只下载了精简版的一个月数据,大约 347M。用 sublime 打开原始数据是乱码的,解决的方案见:如何解决Sublime Text 3不能正确显示中文的问题 - 冷编程 - SegmentFault 思否,然后,打开长这样:
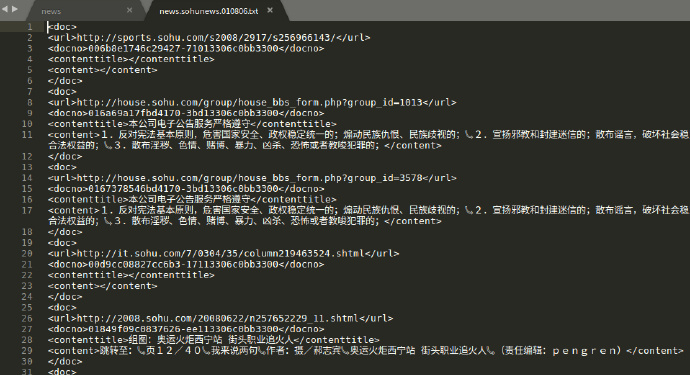
xml的格式,gbk编码,每一个<doc>与</doc>之间是一篇单独的新闻,包含URL、文档编号、标题和正文,其中新闻的分类类别在URL的子域名中,如sports代表体育,house代表房产等等,所以本文只需要拿到URL和content之间的内容就行。
2. 代码解析
OK,背景介绍差不多到这里就结束了,下面是代码实现的解读:
2.1 数据清洗
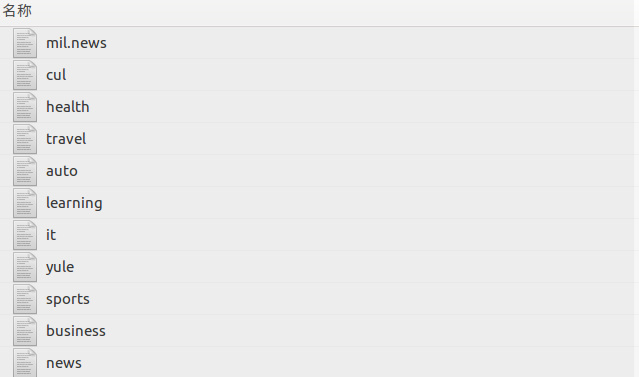
下载下来的原始数据分为129个TXT文件,每个文件中包含有不同类别的新闻数据,我要做的是遍历每个文件,然后把相同类别的新闻提取出来并写入新的文件中。读取中文txt文档乱码依旧是个头疼的问题,话说我至今仍然弄不是很清楚Python的编码模式。读取完成后,提取出URL和content,我们还需要用正则表达式把子域名拿出来,最后得到15个按类别分好的文件,最终留下了11个类别。
1 | #!/usr/bin/python |
然后,看看各个类别下数据量的分布,发现体育、商业、新闻的数量较多,文化类的比较少,数据分布不太平衡,但这并不影响,因为我们并不会用到全部的数据,而是从每个类别中抽取一部分来训练模型。
1 | 7241 auto |
2.2 准备数据
数据清洗完成后,下一步就是为模型准备训练集、验证集和测试集数据, 训练集和测试集按照4:1的比例分配。
1 | def save_file(dir_name): |
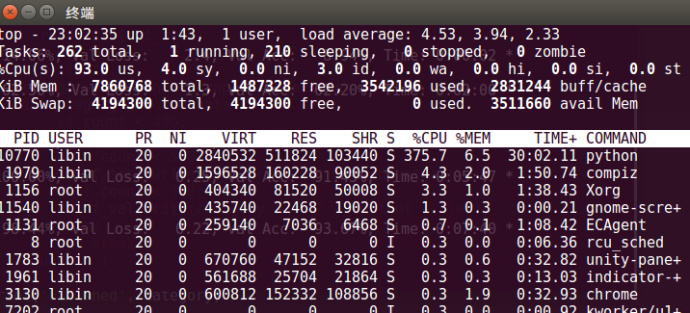
考虑到单机的计算能力,一开始我没有抽取太多的数据,仅仅从每个类别抽取400条作为训练集,100条作为测试集,50条作为验证集。第一组数据测试训练模型时,物理内存占用率并不高,CPU才是最占用计算资源的。下图中显示CPU已经在超负荷工作,而内存无动于衷,在这个基础上开始试着增大数据量。
构建词汇表:vocab
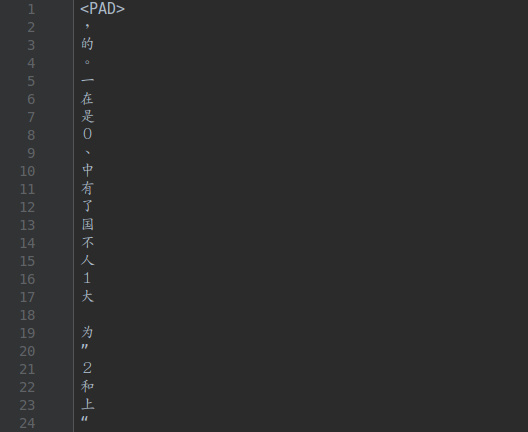
上述的准备工作做完了之后,数据的准备并没有结束,因为我们还没有为字符->向量做好铺垫,通常的做法是加入已经训练好的词向量(比如,这个链接归纳总结的预训练好的词向量就比较全)。在本文呢我没有用它们,而是筛选出的训练集语料中出现频次较高的5000个字符作为词汇表,我比较好奇的是我并没有对原始语料做任何的清洗、去噪,却丝毫不影响分类器的表现。添加一个 <PAD>来将所有文本pad为同一长度
1 | def build_vocab(train_path, vocab_path, vocab_size=5000): |
提取出来的词汇表长这样,停用词、标点符号居多。
词汇表建立好了,txt文件并不适合查询,所以这里用字符在文件的顺序作为其标识的id,存储到字典word_to_id中,这样以来就方便查找了。
1 | def read_vocab(vocab_path): |
类别编码(因变量)
1 | def read_category(): |
处理数据
做完构建词汇表、类别转换为one-hot编码的准备工作,终于要进入正题了,数据进入模型训练、验证、测试前的准备工作还没有做。下面,process_file()函数首先读取数据文件,将正文和标签分别对应存储在contents和labels两个列表中,然后再处理contents中的每一段文本,把文本中每一个字符在词汇表中找到其对应的id,完成文本数值化操作。类别转换为one-hot表示:y_pad = kr.utils.to_categorical(label_id, num_classes=len(cat_to_id))。
1 | def process_file(file_name, word_to_id, cat_to_id, max_length=600): |
2.3 CNN模型设置
CNN参数设置
区别于传统的机器学习,现有任务下,一般的深度学习即使没有经过参数调节也可以达到不错的效果,可见其强大之处。由于上述的原因,往往深度学习也被诟病为“黑箱操作”,因为它比较难以理解,比如对于不太了解深度学习的人,从字符->向量转化过程的理解就比较困难,字符怎么就可以转化成为可以计算的数值呢?就算字符的向量化过程完成了,当有新的数据进入训练模型,它们又是如何从已有的词汇表中匹配到对应的向量?这些都是需要考虑的问题……
解释一下CNN常见的配置参数:
seq_length是输入矩阵的宽度,由输入数据的长度决定,考虑到新闻长度会很长,所以我把矩阵的宽度设置为1000embedding_dim,词向量的宽度,即由现有语料训练得到字向量的宽度,默认设置为64num_classes则根据你实际的类别来设定,设置为11dropout_keep_prob是dropout的比例,一般设置为0.5num_epochs全部数据通过神经网络的次数,决定经过多少轮后停止训练,我在模型中设置为10,实际中有可能没有到10轮就停止了
1 | class TCNNConfig(object): |
文本分类模型
tf.placeholder()是创建占位符,给输入数据腾出空间,第二个参数是占位符的形状,设置为None是为了使模型可以接受任意数量的数据。self.input_x = tf.placeholder(tf.int32, [None, self.config.seq_length], name='input_x')代表创建大小为[None, seq_length]的空间,其中这个空间中的每一行代表了一条输入数据,在CNN模型中我们将其设置为1000,表示只取文本的前1000个字符,之后会用字符在词汇表中的id来对self.input_x填充。
网络的第一层是嵌入层,将词汇映射到低维向量,设置为64,嵌入操作tf.nn.embedding_lookup(embedding, self.input_x)完成后,输出结果是3D张量,形如[None, sequence_length, embedding_dim],对应了下图:
嵌入操作完成后,紧接着便是卷积和池化层,卷积核大小设置为5,表示卷积核每次扫过5个字符,一共有256个卷积核,然后对卷积核生成的feature map做最大池化,池化之后便是第一个全连接层,计算之后dropout掉一些元素,接着是修正线性单元激活函数和softmax层,最后返回softmax层最大值的索引,即预测类别的id。
1 | class TextCNN(object): |
2.4 训练和测试
1 | def train(): |
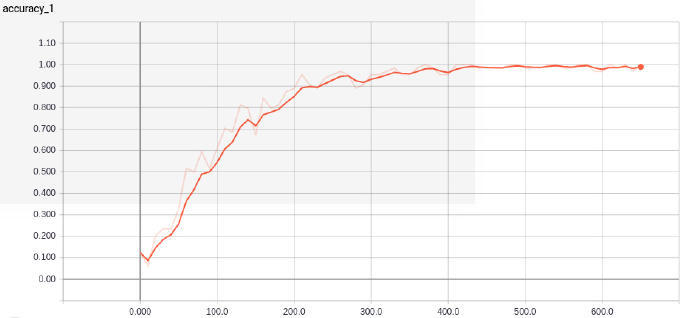
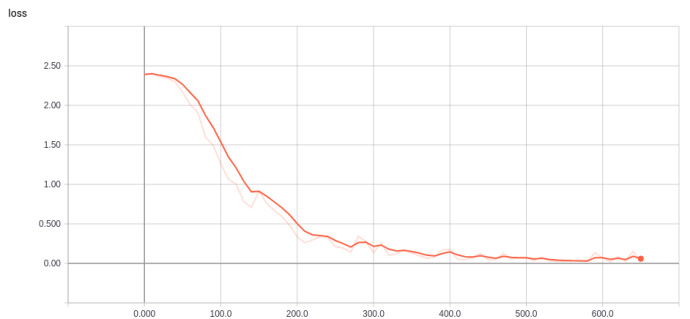
3. 模型训练测试结果
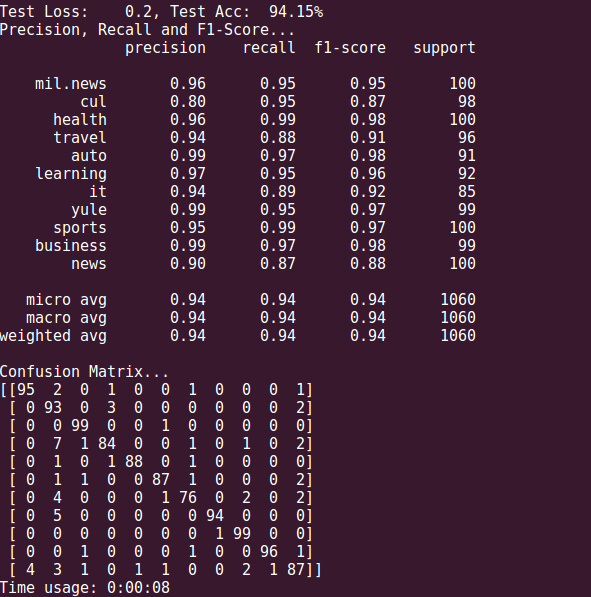
经过10轮的训练,训练集的准确率为98.4%,验证集的最佳准确率94.23%,可能跟数据集较小的缘故,训练收敛得比较快,并且仅仅用了11分钟。
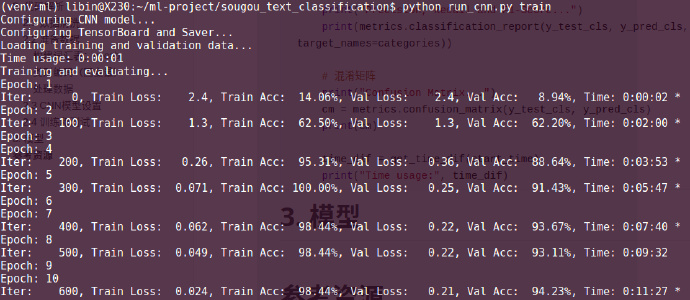
模型在测试集的表现也尚可,达到了94.15%,除了文化类,其他类别的新闻预测准确率都达到了90%以上,召回率也表现不错。
训练过程准确率和损失的可视化结果可以在tensorboard中查看,命令行输入:tensorboard --logdir path/to/eventfile(是文件夹目录)。