sklearn is good tool.
1. 背景
在sklearn下比较各个传统机器学习模型在文本分类任务上的表现。
2. 数据准备
数据源依旧来自搜狗的新闻数据,由于机器的性能,本文只用到了一个星期的数据。
数据清洗
从搜狗下载的新闻数据格式为xml,从HTML标签中提取标签和正文的工作在基于 Tensorflow 的 TextCNN 在搜狗新闻数据的文本分类实践一文中已经完成,不再赘述。因为在本次实验中不再使用基于字符级的思想,而是基于词,所以还要对数据做分词、去噪清洗操作。
分词:使用jieba分词工具,因为在分词时数据是单条单条处理的,所以速度会比较慢,对原始数据采用多进程分词,能节省不少的时间。你可以把多进程理解为把任务列表扔给进程池,“这是交给你的任务,你们赶紧给我办好!”,然后进程池的工人们就迅速过来认领任务,并同时开始工作。
1 | # coding: utf-8 |
多进程分词:
1 | from multiprocessing import Pool |
去噪:原始数据中有标点符号、停用词等噪声,通过加载外部停用词文件过滤掉这一部分的噪声。为了方便,把这两个功能整合成为一个工具类CutWord,在其他程序中直接调用使用即可。
分词、去噪清洗工作完毕,看看各个类别下的数据分布,占比最多的前四个是体育、新闻、商业和娱乐,其余8个类别的新闻占比均不足5%,数据量比较小。因为在这之前我用该数据做了二分类的任务,发现分类效果实在太好了,1万多的测试数据只有十几个分错了,好得有点不真实,所以,我决定拿占比排名前4类的数据来做实验。
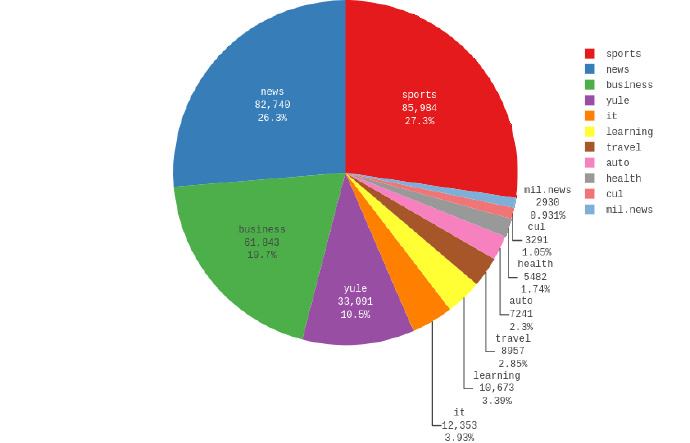
数据切分
每个类别新闻按照5000条训练集、500条验证集、1000条测试集提取,所以总共有训练集:验证集:测试集为20000:2000:4000。
特征提取
sklearn中常用的文本特征提取方法有tfidf,将文本转换为文档-词项矩阵,矩阵中的元素,可以使用词频也可以使用tfidf值。为了获得更好的效果,本次试验的文本特征提取用到了全量的数据。
1 | def tf_idf(contents): |
3. 模型训练
3.1 logistic regression
logitstic regression的背景知识参考我的笔记:机器学习算法系列(3)Logistic Regression | Thinking Realm
为了有更好地优化参数,选用了更有效的交叉验证的LogisticRegressionCV模型,cv设置为10,训练的时间略长;n_jobs设置为-1,利用起所有的CPU核心。
1 | lr_model = LogisticRegressionCV(solver='newton-cg', multi_class='multinomial', cv=10, n_jobs=-1) |
训练结果如下,模型在测试集上的表现还不错,除了体育的准确率为89%,其余的类别的指标都在90%以上。读不懂报告,参考:读懂sklearn的classification_report
1 | [[924 84 0 0] |
3.2 线性支持向量机
支持向量机的背景知识参考我的系列笔记:
1 | svm_model = SGDClassifier(n_jobs=-1) |
强大如支持向量机,30秒不到就完成了训练,按照性价比,完全可以把LogisticRegressionCV摁在地上摩擦。
1 | [[889 118 0 1] |
3.3 朴素贝叶斯
朴素贝叶斯的背景知识参考我的系列笔记:机器学习算法系列(7)朴素贝叶斯法 | Thinking Realm
速度飞快,效果还行。
1 | [[908 99 0 1] |
4. 模型对比
- 文本分类任务,支持向量机的表现可以吊打其他模型
- 一般的数据集的分类任务,各个模型的表现差距不是特别明显,用法大同小异
- 在结巴分词下逐条分词速度很慢,考虑多进程来解决
- 该实验用到的数据量不大,当数据量上升,场景复杂化,参数优化必不可少

