先前仅仅是听RNN这个名词比较多一点,但没有深入去了解,在前一篇文章中我用CNN做了一次文本分类的实践,然后发现RNN也可以完成该任务,所以便开始寻找相关资料学习RNN。我比较推荐台大李宏毅老师的机器学习课程,算是比较清晰易懂的了,没有公式堆砌,完全“人肉手撕”。课程里面有两节专门讲解RNN,第一节讲原理(认真看),第二节讲应用的场景(快速过)。
学完课程,对照PDF课件差不多知道了RNN相比传统的神经网络具有“记忆”的特性,更加注重数据的上下文关系,就不难理解现有语音识别、机器翻译、自动生成等等技术背后的知识,以及RNN最成功的扩展长短时记忆网络(简称LSTM,Long Short-term Memory)。现在,我基本理解了RNN的一些知识,以笔记的形式记录下来。
神经网络比较
回想先前接触的神经网络,前馈神经网络、DNN、卷积神经网络,它们都可以比较好地胜任器学习任务,比如文本分类,这些任务的有一个最大的特点:在建立训练模型的时候不用考虑各个输入之间的关系(上下文),输入与输入、输出与输出都是相互独立的。
现有一个新的场景,如下图,给定一段文字,需要从文字中提取地点和时间信息,用传统的神经网络可以解决,但是如果我们想知道地点到底是“出发”还是“目的地”就不可以了,因为输入“arrive”和“Taipei”之间是独立的,一般神经网络没有办法学习到它们之间的联系,这个时候就需要神经网络拥有“记忆”能力。
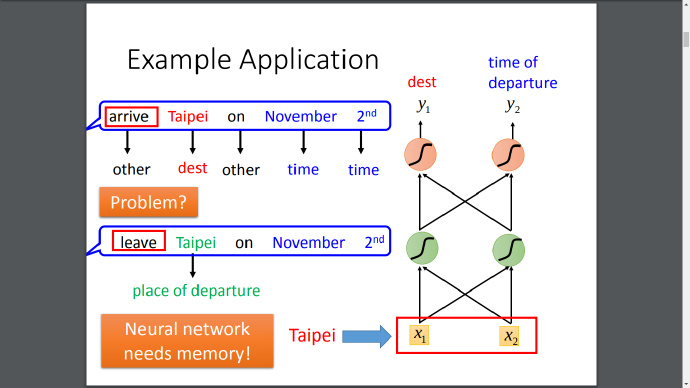
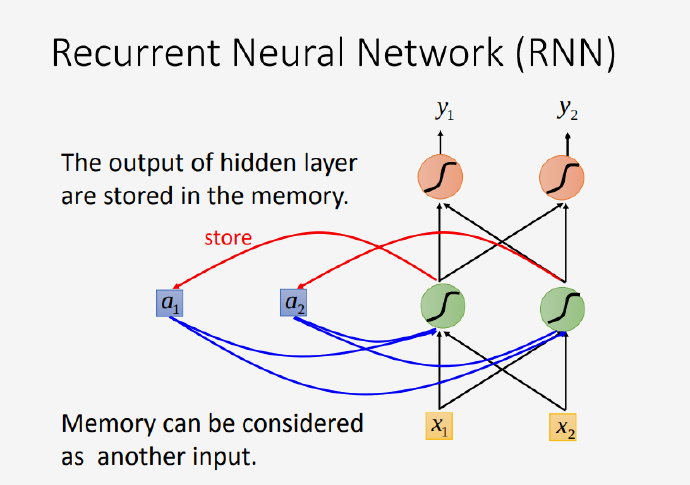
在RNN中会有一个记忆单元,它储存着隐藏层的输出,并把它当做下一次的输入之一。你有可能不明白,为什么是“输入之一”的表述,难道还有多个输入?是的,这就是RNN区别于普通神经网络的地方,上一次的输入对下一次的输入会有影响,正是如此它才拥有记忆力,假如你随意改变输入的序列顺序将会对RNN有很大的影响,一个说话颠三倒四的人不太好理解吧哈哈。
如果你不太理解,建议打开原来的视频看看李老师的教学视频,从7:21开始的地方有一个例子,看完就会理解RNN记忆单元的工作原理,本文就不再复述了。
LSTM结构
上述是RNN最简单的一种形式,当然它还有很多扩展,其中最有名的便是长短时记忆网络,简称LSTM。
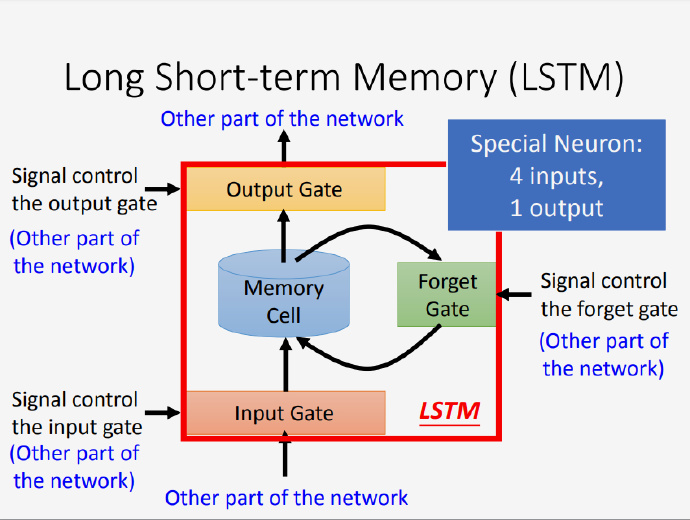
长短时记忆网络,正确的断句应该是“长/短时记忆/网络”,字面意思是在LSTM中RNN会拥有比较长的短时记忆,由遗忘门控制。
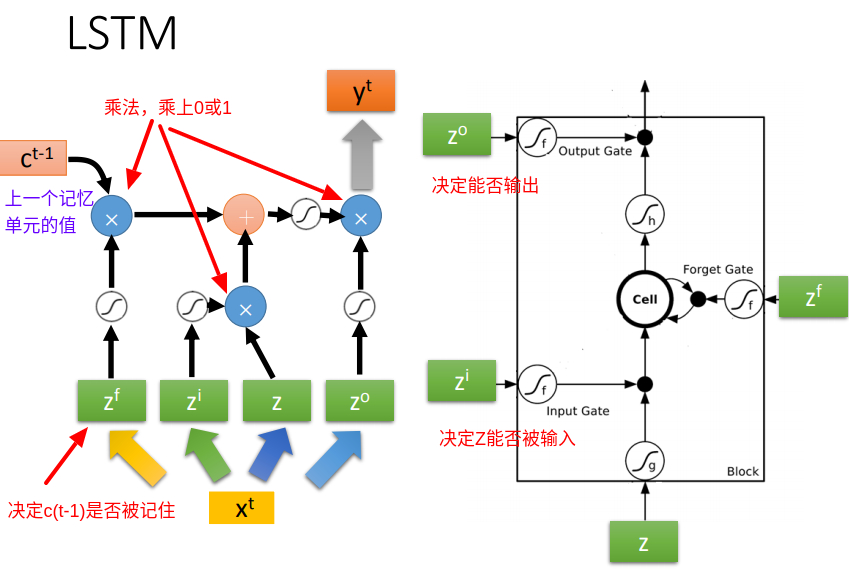
相比最简单的RNN,控制LSTM记忆单元(memory cell)有3个gate,分别是输入门(input gate)、输出门(output gate)和遗忘门(forget gate),所以LSTM这种特殊的神经元有四个输入、一个输出:
- 输入:对应下图指向红色框框的四个箭头
- 输出:红色框框一个对外指向的箭头
所以,LSTM的参数数量会比较多,是一般神经网络的4倍,LSTM的训练会很难,并且loss的波动会很大,看起来会有点“异常”;还有因为在LSTM中网络是有记忆的,参数的扰动会带来很大的影响,有点类似蝴蝶效应,这也是造成loss波动大的原因之一。
计算过程
下图是LSTM的计算过程,输入一共有四个:$Z$、输入门$Z_i$、输出门$Z_o$、遗忘门$Z_f$,一个输出$a$。三个门各司其职,每个门通常使用sigmoid函数作为激活函数,激活后的值处在0和1之间,故方便控制“门”的开启和关闭,输入门决定$Z$能走多远,遗忘门决定记忆单元的值是否刷新或者重置,输出门则决定最后的能否被输出。
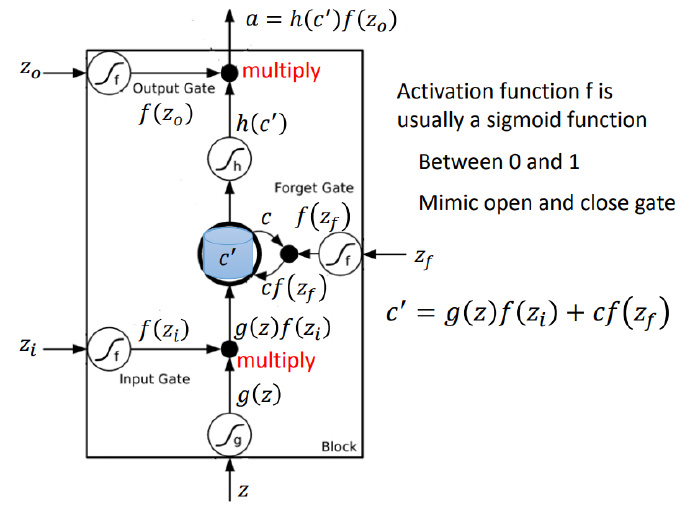
一个LSTM单元的计算过程如下:
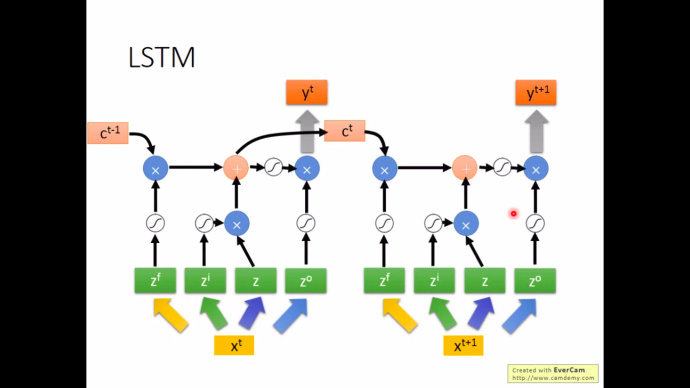
下图解释了在LSTM中上下文之间是如何关联起来的,每个输入$x^{t+1}$都会接受来自上一个记忆单元的值$c^t$
到此,LSTM的基本知识学习完毕,总的来说,李宏毅老师的教学视频是目前为止最通俗易懂的,他的课程值得反复观看理解。当然,LSTM的扩展千变万化,有多层、双向,LSTM的参数多,实现起来比较困难,据说当时只有mikolov一个人的代码能work。还好现在很多框架已经实现了这部分的工作,比如keras、tensorflow等等,直接拿过来用即可,这是我学完课程后,找了一些网上的代码做的一次LSTM文本分类实践:基于 Tensorflow 的 TextRNN 在搜狗新闻数据的文本分类实践 | Thinking Realm。
最后引用一段话作为结尾:
不少搞工程的人认为,要理解什么东西,搞明白其底层数学描述是必要和充分的,你需要“了解背后的数学原理”。其实,在所有场景下,这几乎都不是充分的,也不是必要的——远远不是。以PCA为例,知道怎么做5x5矩阵对角化,算是“知道PCA背后的数学原理”。但这对你了解PCA是什么、能做什么,以及为何有用没太大帮助。你需要更高级的心智模式。 这几乎是普遍的事实:要理解某项事物,你需要正确的心智模式,抓住那些真正关键的方面,而不仅仅是最最底层的数学描述。大多数情况下,两种模式完全正交。深度学习反向传播也是如此——知道怎么写反向传播的程序,并不会让你了解深度学习的实用知识,相反,深入深度学习的心智模式,一定不是以了解反向传播算法细节为中心的。此外,有了正确的心智模式,在需要时可以很容易地自行得出算法细节,至少有效实现是没问题的。 via:François Chollet

