
1. 数据预处理
特征缩放(Feature scaling)的定义参见Feature scaling - Wikipedia
- 无量纲化:不相同规格的特征无法放在一起比较,通常线性转换的手段有:
- 标准化(Standardization):转换成标准正态分布
- 归一化(Normalization):将特征缩放到相同的区间
- 最小最大归一化(Rescaling(min-max normalization)):将数据压缩到[0, 1]区间)
- 均值归一化
- 优势:
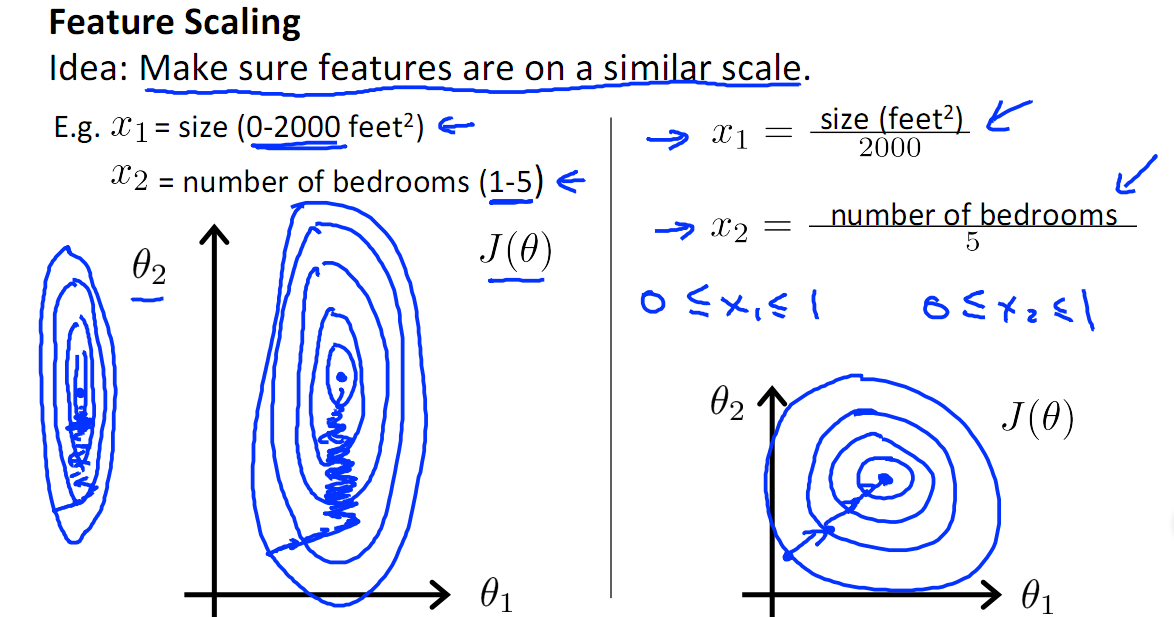
- 向量单位化:针对特征向量单位化(Scaling to unit length),使其长度为1
- 定量特征:二值化
- 定性特征:one-hot编码
- 分类特征编码
- 特征组合:基于多项式的、基于指数函数的、基于对数函数
归一化与标准化的比较,参见特征工程中的「归一化」有什么作用? - 微调的回答 - 知乎 。
2. 特征选择
为什么要做特征选择?
- 简化模型便于解释
- 缩短训练时间
- 避免维度灾难
- 提高模型的泛化性能,比如通过减少过拟合
一般,特征选择有三个思路:
- 基于过滤(Filter)
- 方差检验:去掉那些方差不符合阈值的特征,方差很小代表它对区分样本的作用不大,见sklearn.feature_selection.VarianceThreshold — scikit-learn 0.20.0 documentation
- 相关性检验:优先选择与目标变量相关性高的特征
- 相关系数
- 卡方检验
- 互信息检验:经验熵与条件熵的差称为互信息(信息增益),信息增益大的特征具有更强的分类能力
- 基于嵌入(Embedded)
- 正则化:L1、L2正则化
- 基于树:随机森林、GBDT
- 基于包裹(Wrapper):典型的是递归特征消除算法(recursive feature elimination algorithm)
- 学习器返回的 coef_ 属性获得每个特征的重要程度
- 从当前的特征集合中移除最不重要的特征
- 重复递归这个步骤,直到最终达到所需要的特征数量为止
- sklearn.feature_selection.RFE — scikit-learn 0.20.0 documentation
- 特征选择(5)-递归消除法 | 算法之道

