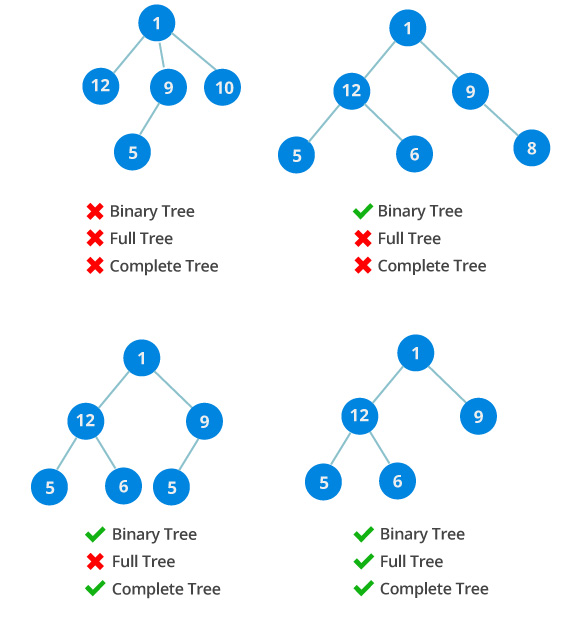
完全二叉树的特点(百度百科):
一棵二叉树至多只有最下面的两层上的结点的度数可以小于2,并且最下层上的结点都集中在该层最左边的若干位置上,则此二叉树成为完全二叉树,并且最下层上的结点都集中在该层最左边的若干位置上,而在最后一层上,右边的若干结点缺失的二叉树,则此二叉树成为完全二叉树。
完全二叉树具备以下特点:
- 叶子节点只能出现在最下两层
- 最下一层的的节点可能没有右子节点,如果只有一个节点,那么它必须是左子节点
- 除了最下面两层,每个节点必须有且仅有两个子节点
从完全二叉树回到堆排序,堆排序分为三个步骤:
- 首先,我们需要从已有的数组构建最大堆,然后,已有数据的最大值会位于堆的最顶端(root node)
- 最大堆一旦建立,将最大值(root node)与数组最后一个元素交换,并从堆中删除最后一个node
- 只要堆的大小大于1,重复1-2步骤
堆排序的时间复杂度:
堆排序是一种原地排序(inplace)算法,不需要分配额外的内存空间,它的运行时间主要消耗在了构建堆和重建堆时的反复筛选上了,它对原始数据的排序状态并不敏感,总体来说,无论是最好、最坏还是平均,堆排序的时间复杂度都为$O(nlogn)$。
下面是堆排序的Python实现:
1 | # Python program for implementation of heap Sort |

