典型RNN模型
下图是典型的RNN模型,$X$是输入,对文本经过嵌入层嵌入处理,再进入RNN,RNN的后面是全连接层,输出各个类别的概率。
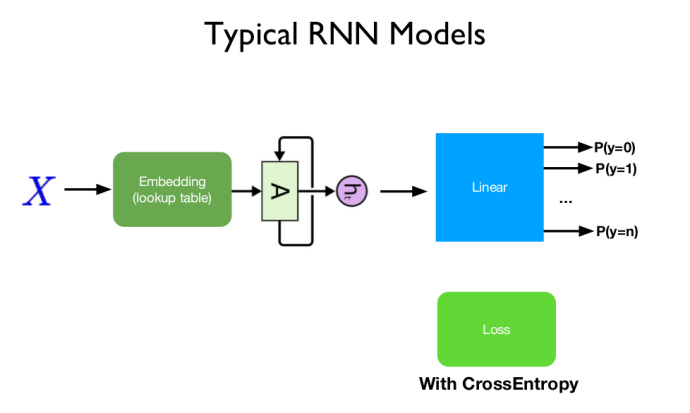
下面来描述一次数据从输入到输出的完整过程:
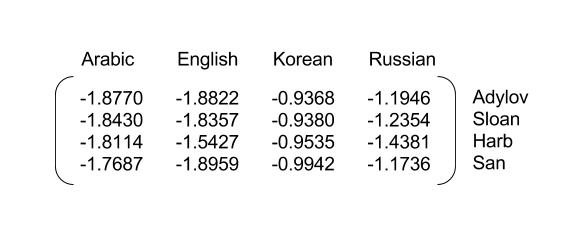
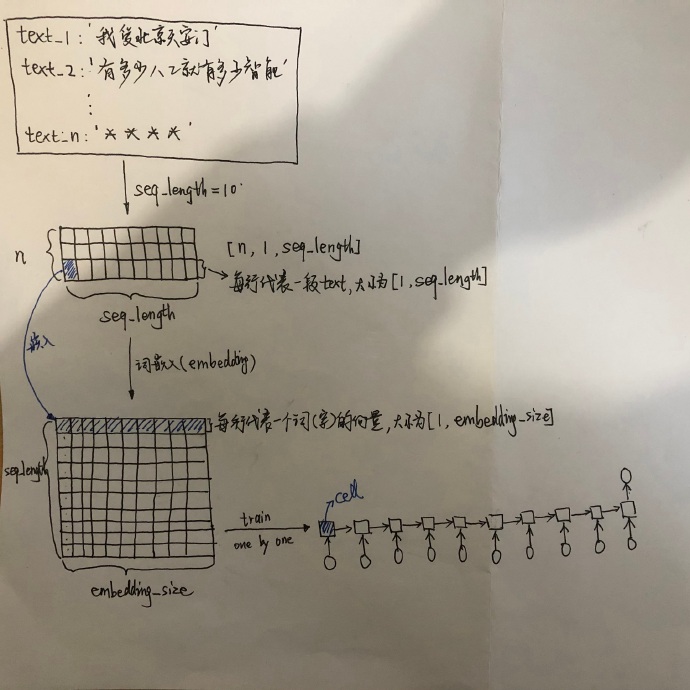
在自然语言处理中,不管是中文还是英文,首先第一步的任务是如何将文本数据数值化。对于中文,可以先建立词汇表,给词汇表中的没歌词建立唯一的id标识(数字),这样每段文本都可以用一串数字id来表示,然后就能进行词嵌入操作,英文的处理方法也类似。
对文本预处理时,由于每条文本的长度不一,需要给输入统一规定长度(seq_length),超过的截断,不足的填充。假设有$N$段文本(text),统一长度后就变成了[N, 1, seq_length]大小的矩阵,矩阵的每一行代表一段文本,大小为[1, seq_length]。
通常,传统的做法是将one-hot编码,但是劣势是矩阵会很稀疏,并且上下文之间的语义关系非常模糊,难以捕捉。现在一般的做法是将文本词向量化,将每个词(字)“嵌入”为大小为[1, embedding_size]大小的向量矩阵。到了这一步,输入基本就确定下来了,它是大小为[seq_length, embedding_size]大小的矩阵。
接下来是训练,训练中可以一条一条给RNN“喂”数据,当有一条数据进来,等待它的是seq_length个cell,LSTM的输出整个过程如下:
但是这样的训练太慢了,并且优化的参数也难以顾及到全局的信息,通常是批次训练,一次喂给模型batch_size条数据。
批次训练全过程详解
1. one-hot 编码

2. 零填充

3. 批量输入
将每一个batch设置为4
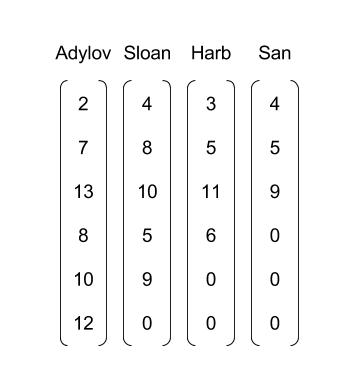
4. 词嵌入(word embedding)
矩阵中的每一行代表一个字母的向量
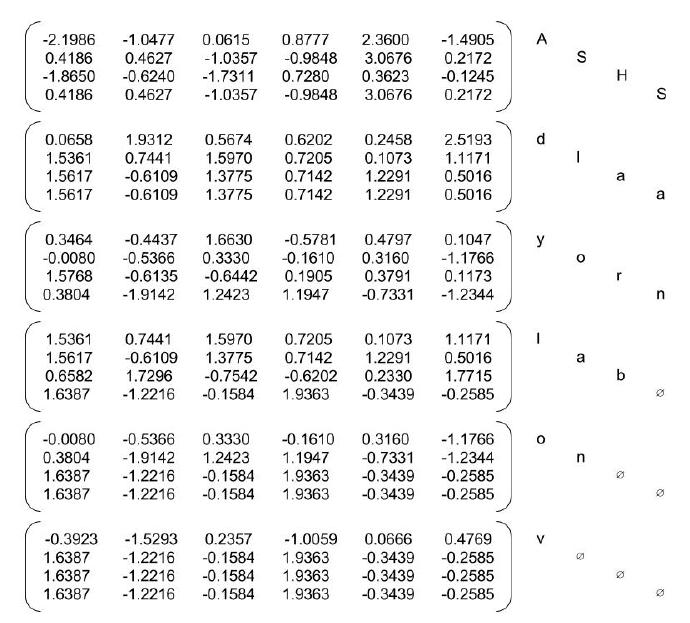
5. Packed Embeddings
注意,这里将词向量矩阵打包过了一次,因为我们并不需要零填充后的词向量。在这种情况下,batch_sizes为[4, 4, 4, 3, 2, 1],即第一步到第三步每次会给LSTM喂4个字母,到第四步,San已经用光了,所以给LSTM的只有3个字母,以此类推,到最后只有1个字母v。
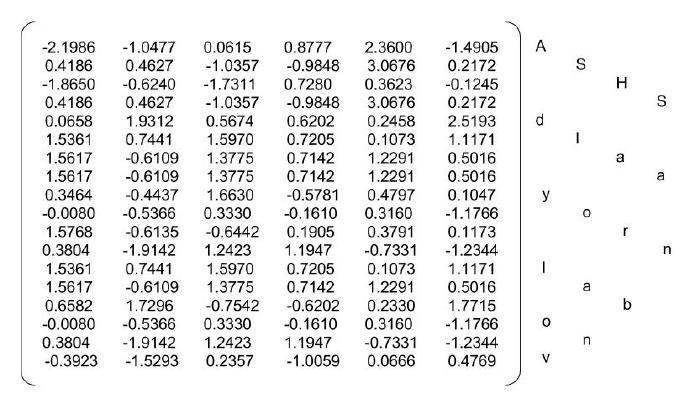
6. LSTM out
数据进入RNN之后输出的结果
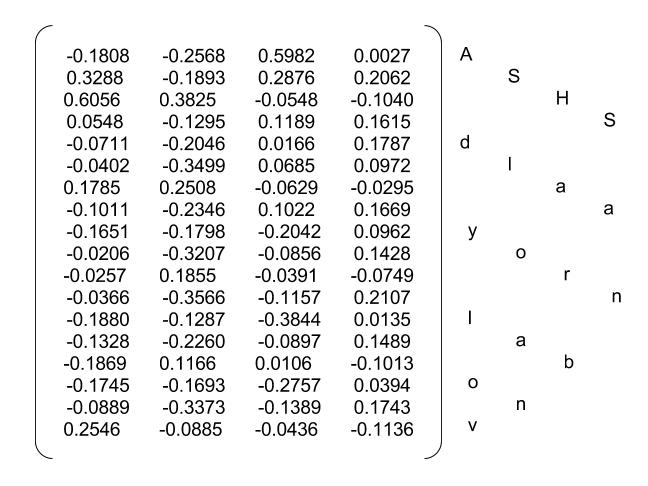
7. padded LSTM out
填充LSTM的输出
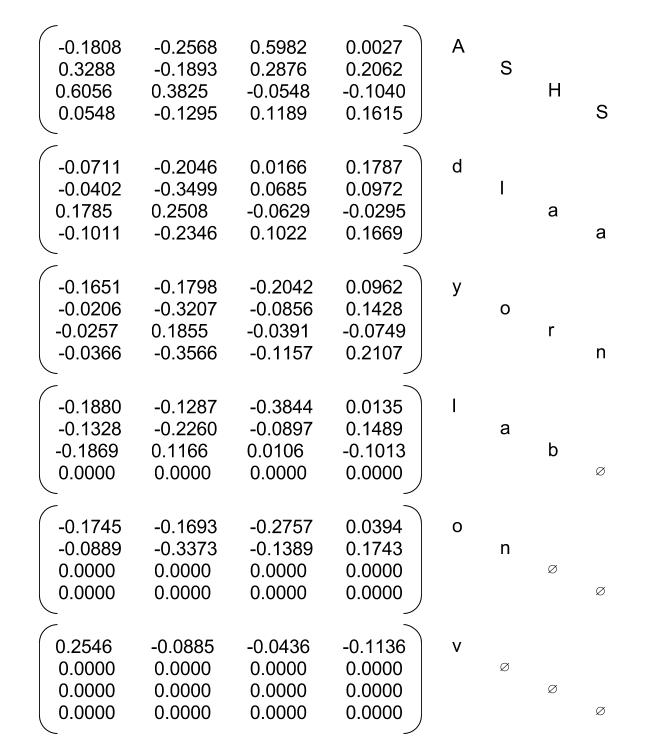
8. reshape output

9. maxpooling
最大池化
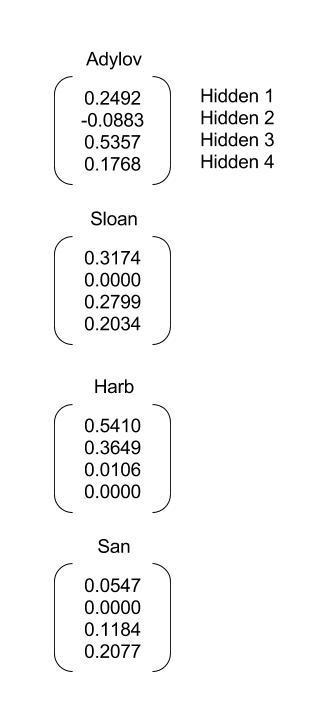
10. predict