在 pandas 下,可以对多种不同类型的数据进行粘结,包括 DataFrame、Series,甚至字典都可以合在一起,可以说是“万能胶”了。
在 Python 中 Pandas 提供了许多组合数据的手段,下面主要介绍 concat 的用法。
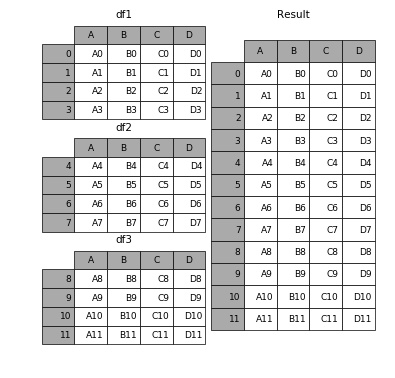
现有3个 DataFrame 分别是:df1、df2、df3:
1 | df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], |
使用 Pandas 将3个 DataFrame 组合起来也是特别简单的,只需
1 | result = pd.concat([df1, df2, df3]) |
假如将 DataFrame 组合起来后,又有从 result 中提取 DataFrame 的需要呢?只需要在组合的时候添加 keys 参数就好了。
1 | frames = [df1, df2, df3] |
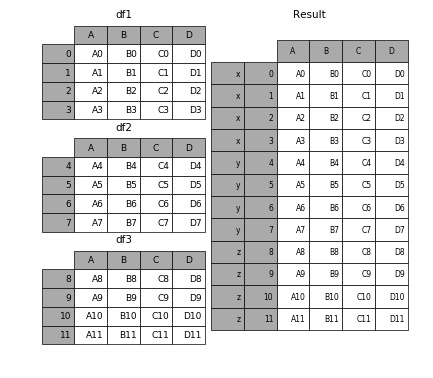
如果需要提取 df2,
1 | In [7]: result.loc['y'] |
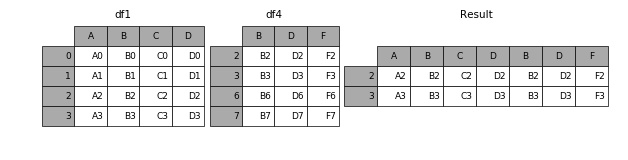
在拼接 DataFrame 时,通过设置参数join你还可以决定只拼接哪些轴,比如,有 df4,
1 | df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'], |
在默认情况下,pandas 会将两个 DataFrame 完全粘结起来,这种连接方式保证了信息的零丢失,
1 | # 默认join='outer' |

当参数设置为join='inner',可以理解为从两个 DataFrame 中取交集,
1 | result = pd.concat([df1, df4], axis=1, join='inner') |
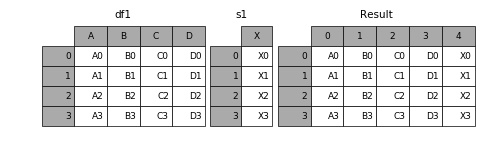
当然,Series 也可以与 DataFrame 连接,比如,
1 | s1 = pd.Series(['X0', 'X1', 'X2', 'X3'], name='X') |

如果不喜欢 Series “讨厌”的名字,设置参数ignore_index=True便可以去掉重新索引,
1 | result = pd.concat([df1, s1], axis=1, ignore_index=True) |