一、Hadoop下载和添加环境变量
稳定版Hadoop下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/,选择大小为204M名为`hadoop-2.7.3.tar.gz`的安装包,然后解压到硬盘(我的放在E盘了)。
添加环境变量
添加“HADOOP_HOME”系统变量,并添加到系统变量的Path中,按照下图操作
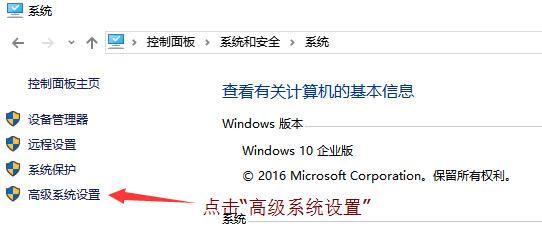
1.找到“高级系统设置”
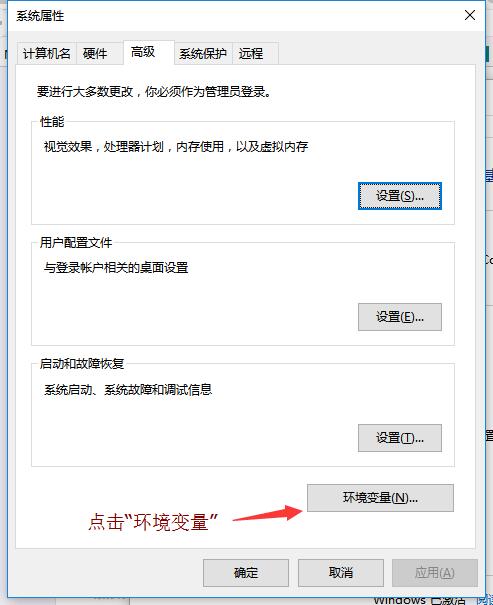
2.点击“环境变量”
3.新建系统变量
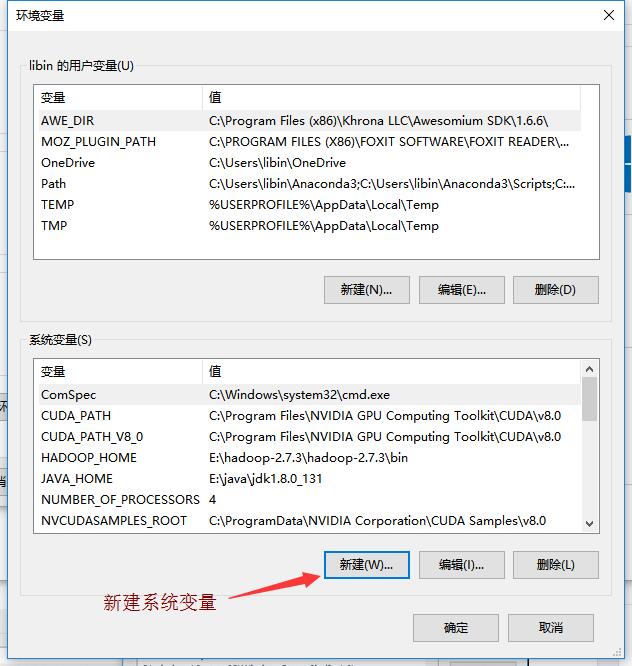
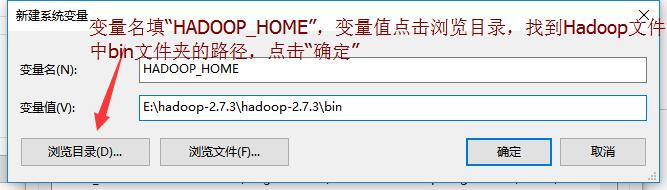
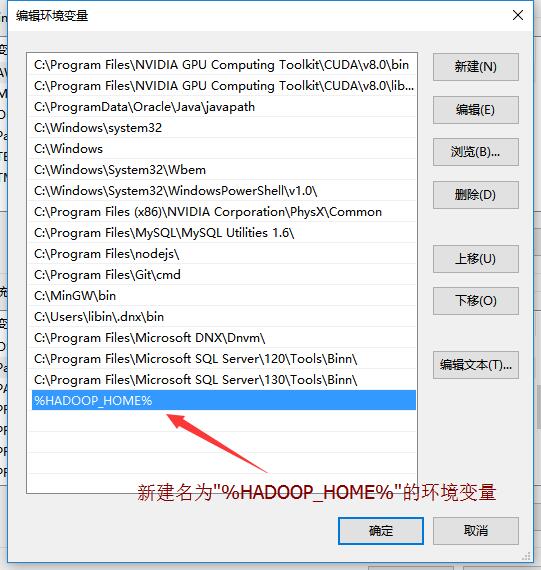
4.将新建系统变量添加到
Path中
二、安装JDK
JDK的安装很重要!!!
JDK(Java SE Development Kit)是使用 Java 编程语言构建应用、小程序和组件的开发环境。JDK下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html,根据计算机操作系统(我的是Windows64位),选择下载相应的安装包。
jdk默认会安装在C:\Program Files下,而这样做是不可以的,因为在接下来配置Hadoop的时候,Hadoop会因为C:\Program Files路径中有一个空格而出现JAVA_HOME无法找到的错误。
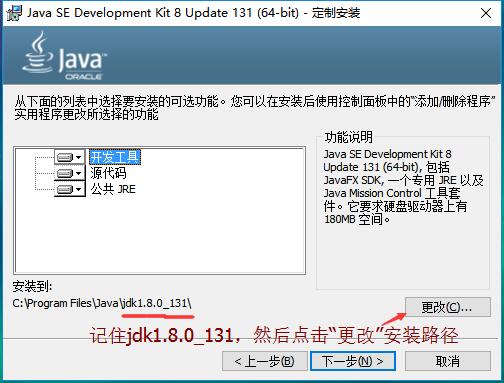
所以,我在E盘下新建了一个名为java(记住文件夹名不能有空格!)的空文件夹用于安装jdk,然后点击jdk安装包
1.记下jdk版本号,更改安装路径
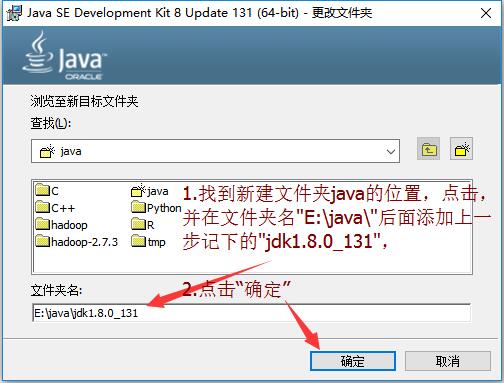
2.找到目标安装文件夹,填写版本号
3.点击“下一步”
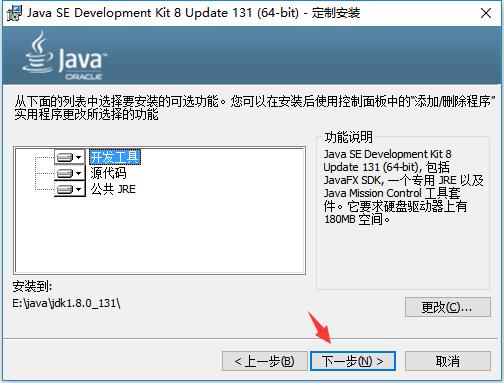
4.因为我事先已经安装了Java,所以安装jdk时,jdk会提醒我一并安装Java,但是这并不需要,所以放心关闭就好
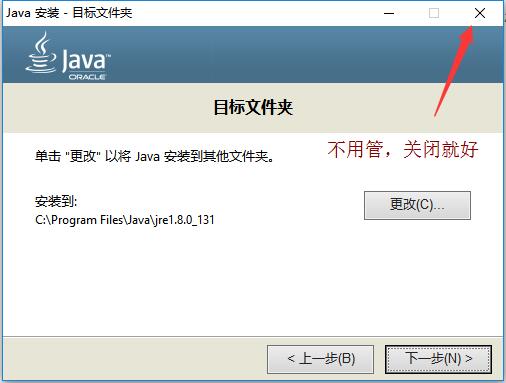
5.点击“否”
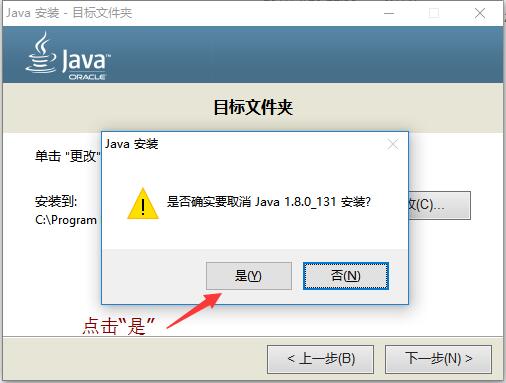
6.jdk安装成功,可以看到安装文件已经在安装路径下了
到此为止,Hadoop环境变量的配置和jdk的安装完成了,Hadoop的安装差不多完成一半了。
三、配置Hadoop
配置Hadoop的四个关键文件如下:
| 文件名称 | 格式 | 描述 |
|---|---|---|
| hadoop-env.cmd | Windows命令脚本 | 记录脚本中要用到的环境变量,以运行Hadoop |
| core-site.xml | Hadoop配置XML | Hadoop Core的配置项,例如HDFS和mapreduce常用的I/O设置 |
| hdfs-site.xml | Hadoop配置XML | Hadoop守护进程的配置项,包括namenode、辅助namenode和datanode等 |
| mapred-site.xml | Hadoop配置XML | mapreduce守护进程的配置项,包括jobtracker和tasktracker(每行一个) |
下面给出我的配置信息,大家打开文件后直接添加便可
1.编辑
hadoop-2.7.3\hadoop-2.7.3\etc\hadoop\hadoop-env.cmd文件
1 | @rem The java implementation to use. Required. |
2.编辑
hadoop-2.7.3\hadoop-2.7.3\etc\hadoop\core-site.xml文件
1 | <configuration> |
3.编辑
hadoop-2.7.3\hadoop-2.7.3\etc\hadoop\hdfs-site.xml文件
1 | <configuration> |
4.编辑
hadoop-2.7.3\hadoop-2.7.3\etc\hadoop\mapred-site.xml文件
1 | <configuration> |
5.编辑
hadoop-2.7.3\hadoop-2.7.3\etc\hadoop\yarn.xml文件
1 | <configuration> |
四、格式化并启动Hadoop
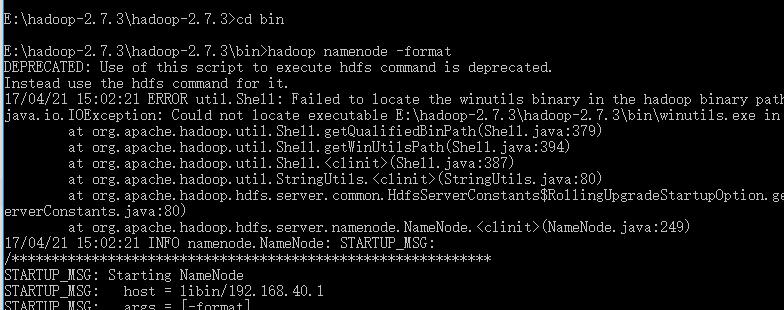
格式化HDFS文件系统,hdfs namenode -format
打开cmd,cd到\hadoop\hadoop-2.7.3\sbin,输入start-all,启动Hadoop,同时弹出四个窗口,Namenode、Datanode、YARN resourcemanager、YARN nodemanager四个进程启动成功。
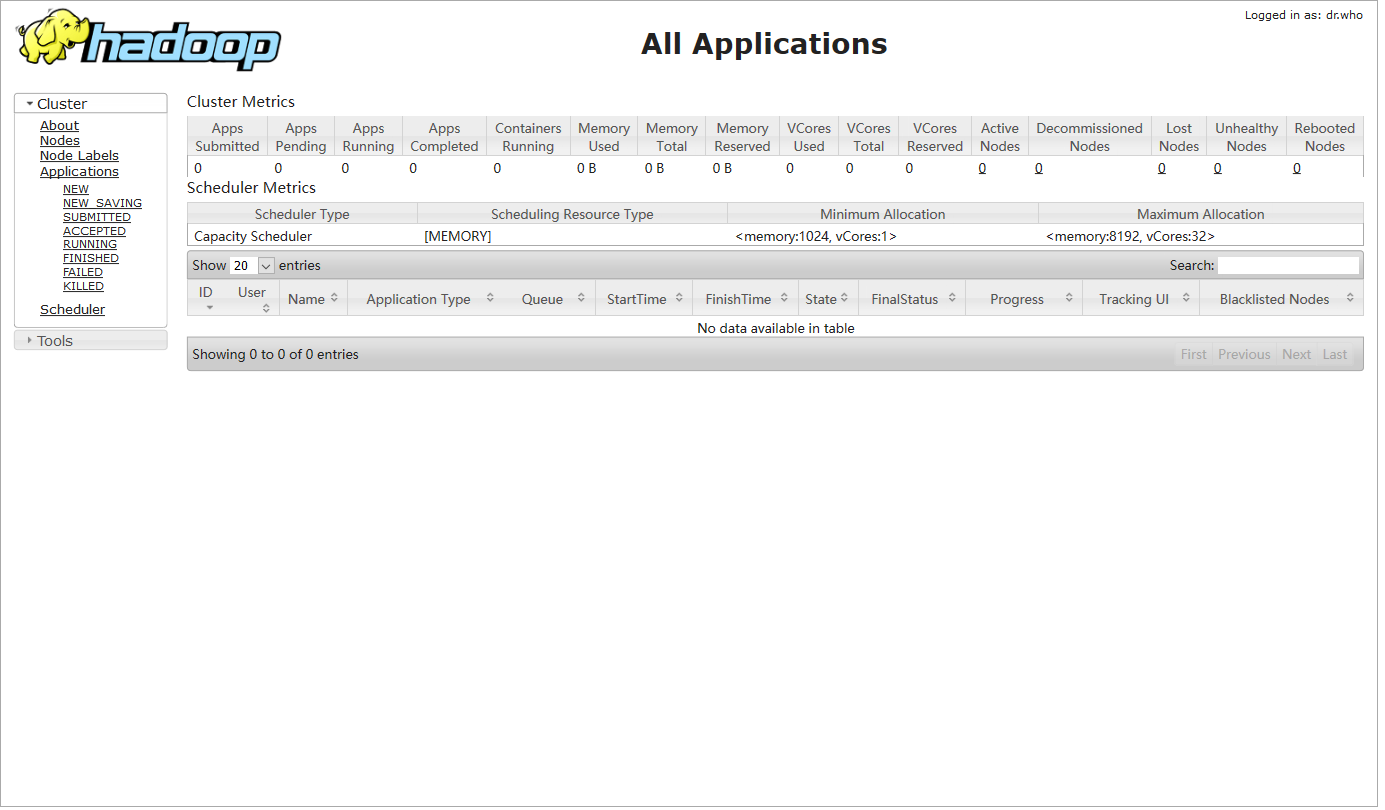
打开localhost:8088,进入web页面,Hadoop安装成功。
参考
1.http://toodey.com/2015/08/10/hadoop-installation-on-windows-without-cygwin-in-10-mints/

