
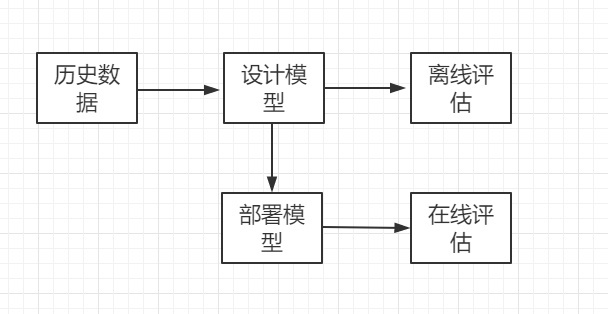
1. 机器学习模型开发和评估的流程
统计学习方法的基本假设是同类数据具有一定的统计规律性,它的研究对象是数据,从数据出发,提取数据特征,抽象数据模型,发现数据中的知识,又回到数据的分析与预测中。统计学习方法(一般指的就是机器学习)的三个要素:
- 模型
- 策略
- 策略能够帮助我们选择最优模型,通过损失函数来度量模型的好坏
- 计算损失函数的期望是模型关于联合分布下平均意义上的损失,由于联合分布未知,期望损失是无法直接计算的
- 在大数定律下,当数据量趋近无穷大时,经验损失趋向于期望损失,所以,我们希望借助于用经验损失来拟合期望损失
- 经验损失的计算通常会遇到过拟合的问题
- 算法
- 如何保证找到全局最优解?
统计学习方法的步骤:
- 得到一个有限的训练数据集合
- 确定包含所有可能的模型的假设空间,即学习模型的集合
- 确定模型选择的准则,即学习的策略
- 实现求解最优模型的算法,即学习的算法
- 通过学习方法选择最优模型
- 利用学习的最优模型对新数据进行预测或分析
2. 分类模型的评估指标
2.1 准确率
2.2 混淆矩阵

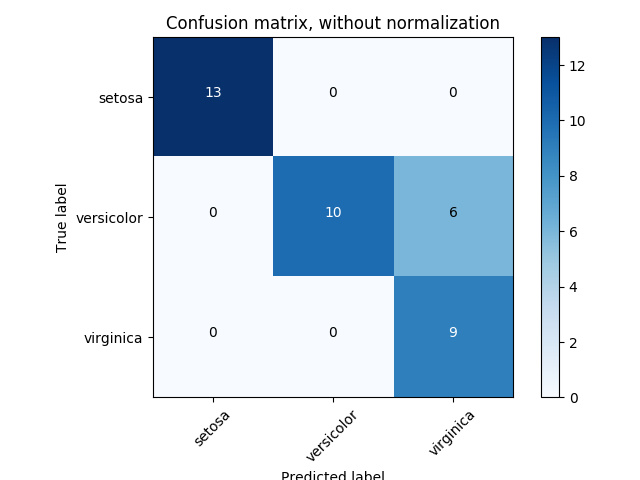
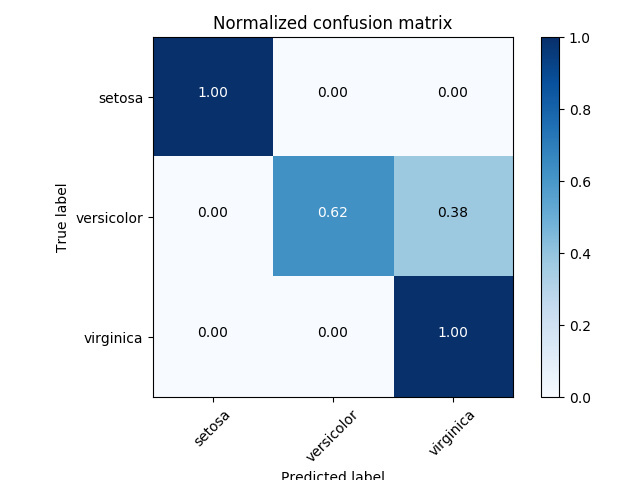
2.3 ROC 曲线
ROC 曲线是一种研究机器学习泛化性能的工具,它用到了两个重要的指标:真正例率(TPR)和假正例率(FPR)。在测试数据上,机器学习模型会得出一个预测值或概率值,然后我们用分类阈值(threshold)$x$ 与预测值或概率值进行比较,比如大于 $x$ 判为正例,小于 $x$ 判为负例。
当分类阈值最大时,没有一个点划为正例,此时 TP 和 FP 都等于零,真正例率和假正例率都为零,对应 ROC 曲线的 A 点;最理想的情况是 B 点,此时的真正例率为 1 而假正例率为 0;分类阈值最小时,所有的样本都划为正例,故 TN 和 FN 都都等于零,则真正例率和假正例率都为 1。
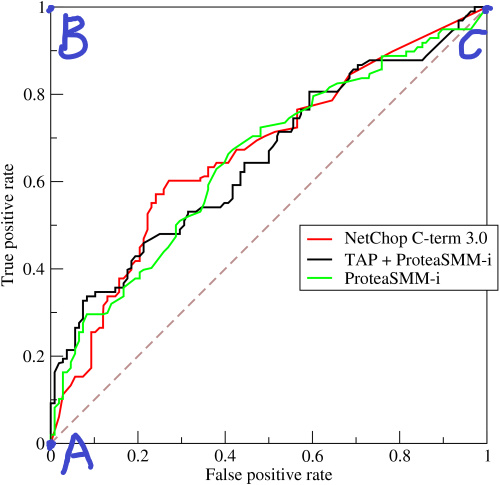
AUC(area under curve),即曲线下的面积,AUC 是度量 ROC 曲线的一种方法,好的模型 ROC 曲线下的面积会很大,因此 AUC 越大越好。
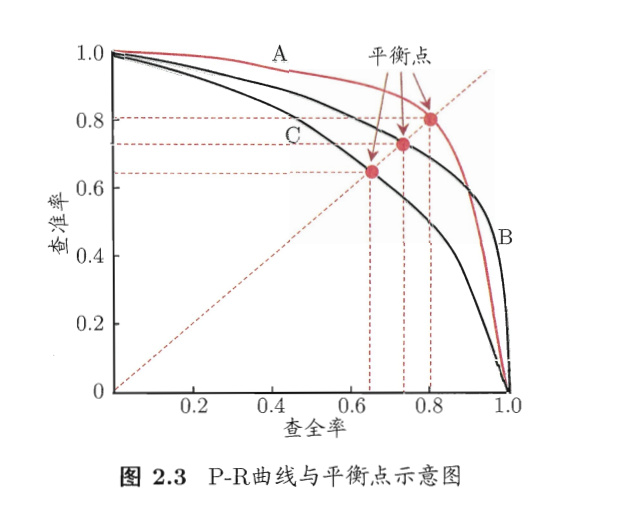
2.4 查准率和召回率
疾病诊断为例,查准率指的是诊断结果中有多少是真正患病的,召回率指的是有多少真正患病者被诊断出来了,F-1 值则是查准率和召回率的调和平均值。查准率和召回率是评估分类模型中最常见的一组指标,在工程实践中通常用不同阈值与模型得出的预测值或概率值进行比较,然后比较这几组查准率和召回率的优劣。
3. 回归模型的评估指标
3.1 均方差
回归模型中用得最多的度量指标是均方差(mean square error)
3.2 Root Mean Squared Log Error
3.3 灵敏度和特异度
灵敏度(Sensitivity),跟真正例率的定义一样,指真正例中被模型发现的比率,所以灵敏度又可以称为召回率。
特异度(specificity),指真负例中被模型发现的比率,也可以看做是负样本的召回率。
3.4 R-Squared
在线性回归以及广义线性回归中,R-squared 误差的大小意味着模型的拟合度的好坏。R-squared 误差取值范围为 0 到 1,这个值越接近 1 说明模型的拟合度越好。
- TSS:Total Square Sum / 总离差平方和
- RSS:Residual Square Sum / 残差平方和
- ESS:Explain Square Sum / 解释平方和

