最近几天花了点时间写了一个爬虫,过程不太复杂,但是对我这样的爬虫小白来说还是花了点时间的。没有涉及到太多技术,收拾的拦路小妖怪倒是不少,下面记录一下具体的实现过程。

我的需求是抓取历年中国地方政府工作报告全文,简单 Google 一下发现没有现成的数据集,或许再花点时间也可以搜索到或者找别人可以要到,为了多写点代码,最终还是决定通过自己动手写爬虫抓取下来。经过搜索,中国经济网整理了从 2003 年到 2017 各省、直辖市、自治区的政府工作报告数据,目标网址是: http://district.ce.cn/zg/201702/26/t20170226_20529710.shtml,粗略统计约 700 多篇,不算很多,对数据感兴趣的读者可以访问链接下载使用:https://pan.baidu.com/s/1clUF2Q 密码:uxg1
在代码中用到的库有 urllib 、BeautifulSoup 、pandas 等,urllib 负责从 URL 地址中请求得到 HTML 标签数据,urllib2 是 python 自带的模块,不需要下载,urllib2 在 python3.x 中被改为 urllib.request。BeautifulSoup 负责解析 HTML 数据,剩下的工作就是编写几个小功能函数了,最后再将这些函数组装起来。
1. 实现思路
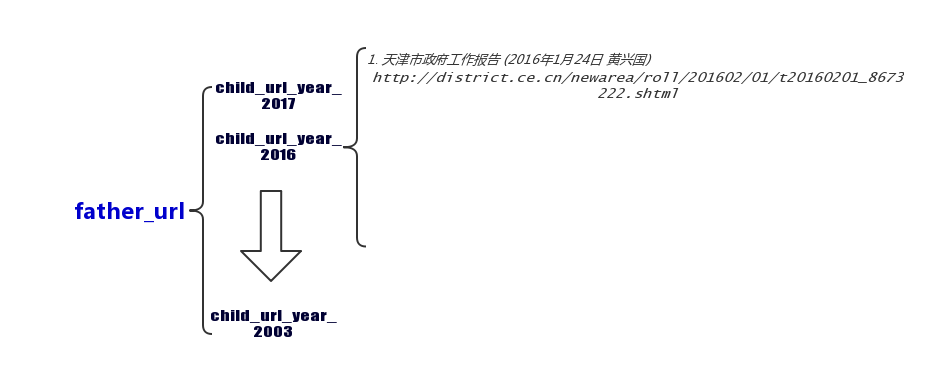
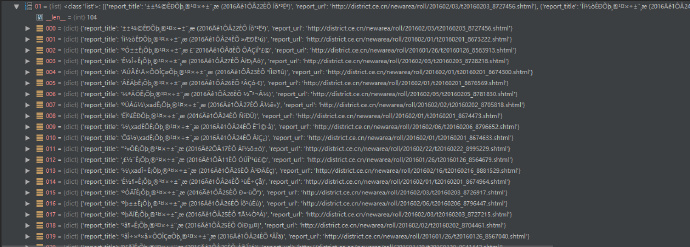
说一下具体的实现思路,这里我们先将 http://district.ce.cn/zg/201702/26/t20170226_20529710.shtml 称为父网址(father_url)好了,这个网址列出了从 2003 年 到 2017 年地方政府报告合集的链接。首先从父网址解析得到历年报告合集页面的 URL 地址,如“2017 年汇编”的 URL 地址是 http://district.ce.cn/zg/201702/26/t20170226_20528713.shtml,我们称之为子网址(child_url_year);然后,再从子网址中解析得到某个年份地方政府报告的 URL 地址(child_url_city)。当我们得到了所有报告的标题(report_title)和链接(report_url),接下来的工作就很简单了,只需要从一个一个的链接中提取出正文即可。
2. 遇到的几个坑
但是在实现过程中还是遇到了几个小问题需要解决:
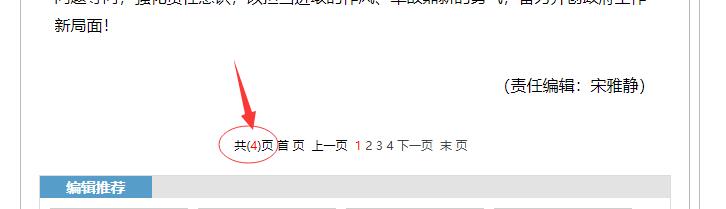
2.1 一般报告不止一页,如何知道总页数?
刚遇到这个问题,我准备打算做个简单粗暴的遍历去实现,一旦解析 404 后直接跳出,后来一想效率太低并且也不太好看。然后在网页源代码中找到这么一段,报告的页数统计是用 js 实现的,也就是动态的,所以 HTML 代码中解析不到页数统计的数据,而是隐藏在一段被注释 js 的代码中。比如,下面这段代码中,页面总数 4 就在 createPageHTML(4, 0, "t20170207_20021665", "shtml") 里。
1 | <!-- |
在这里,我用了一个正则表达式把参数取了出来
1 | tmp_html = standard_html.find_all('script', language='JavaScript') |
2.2 爬取速度变慢
编写爬虫中,考虑到数据量并不大,一开始并没有设置请求的代理头、也没有为 urllib 设置超时,所以在抓取数据的时候,爬虫程序经常超时或者 HTTP Error 502。幸好伪装浏览器解决了这个问题,否则得要按照前辈说的上代理池了。
1 | headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'} |
关于如何伪装浏览器见:https://zhidao.baidu.com/question/2117242032496816307.html
2.3 爬取速度过于频繁
这里我采取了一种比较笨的办法,每访问一次网站就间隔几秒或者随机间隔几秒,经过这个设置后,网站终于没有限制抓取了。这应该不是长久之计,毕竟效率太低了。
2.4 两次面临 HTML 解析器选择
之前写爬虫时用得最多的 HTML 解析器是 html.parser,后来在使用的过程中发现,html.parser 的容错率太低了,很多好端端网页的源代码抓下来一解析就变乱码了,比如这个网址:http://district.ce.cn/zg/201602/04/t20160204_8740940.shtml。开始,我认为是编码的问题,但是后来马上又否定了,中经网所有的网页都是采用 gb2312 的编码,为什么其他网址解析正常,唯独偏偏这个网址就出问题?

苦苦思索无果后,我在一个爬虫交流群里提出了这个问题,热心的群友亲自在本地给我测试了一下这个网址,一切正常。为什么?比较代码之后才发现,是 HTML 解析器的缘故,把 html.parser 换成了 lxml,岁月静好。

第二次面临的选择则是在获取报告正文总页数上,解析又出现了错误,总页面数解析不到,再次把 lxml 换成 html5.lib,岁月静好。根据这轮踩坑,如果求稳的话,以后优先选择 html5.lib 作为第一解析器。
关于解析器的选择,见 BeautifulSoup 文档中的比较:安装解析器
2.5 URL 地址或标题非法导致文件写入不成功
爬下来的数据往往不是你想象中的那么干净,数据永远是脏的,比如报告的链接地址和标题就有各种奇奇怪怪的情形,比如标题中混入了 \xa0、不是报告的 URL 或者有标点符号,又或者 URL 地址不合法导致无法访问。所以,这里采取的解决办法是在抓取的时候过滤掉这些地址
1 | if re.match(r'^https?:/{2}\w.+$', province_report_url) and |
2.6 异常处理
异常处理非常重要!!!
在异常处理这块踩了好多坑,你一定不想看到程序跑了一个小时候突然因为一粒“老鼠屎”而挂了吧?记住,进行字典处理、文件 IO 的时候一定一定要考虑异常,火星人,地球是很危险的,一不小心会挂。
3. 实现代码
其他的后续再补充,下面是代码,欢迎指正!
3.1 过滤年度报告的标题及地址
1 | #!/usr/bin/python |
3.2 遍历所有的地址并抓取全文
1 | #!/usr/bin/python |
后记
本次爬虫的数据量很少,总共也就不到 700 篇,真正恼人的是时不时蹦出的小错误。当然,这个爬虫的代码很烂,根本没有考虑效率因素,大规模的爬虫实践肯定不是这种操作,后面有时间再实践实践多线程、多进程、ip 代理池的技术。
推荐阅读
- http://wiki.jikexueyuan.com/project/python-crawler-guide/advanced-usage-of-urllib-library.html
- python 高度健壮性爬虫的异常和超时问题
- http://www.cnblogs.com/ly5201314/archive/2008/09/04/1284139.html
- http://caibaojian.com/zhongwen-regexp.html
继续阅读本站其他精彩文章

