写在前面
没想到博客能存活到现在,全凭着一股兴趣,不知不觉这个系列已经写到第 13 篇了。一直以来,我都是抱着初学者的心态来写机器学习算法,限于专业以及其他因素,圈子内有同样兴趣的伙伴少之又少,所以对机器学习的理解大多来自独自阅读论文和观看教学视频,个人的理解难免出现低级错误。再加上本人又非科班出身,遇到难以理解的地方往往“求告无门”,只能翻来覆去的啃,铺天盖地地搜,难免陷入主观的境地。
本文主要写的是笔者对 CNN 原理的一些个人理解,在 CNN 如何进行学习以及 dropout 没有做太多涉及,笔者接触卷积神经网络(Convolutional Neural Network,以下称 CNN)的时间不长,不论是看的论文还是做的 project 都远远不够,出现错误在所难免,理解上出现的偏差我是要负主要责任的,欢迎大家帮我找出文章中纰漏!
Regular Neural Nets don’t scale well to full images.
在之前的一篇文章中:机器学习算法系列(8)神经网络与 BP 算法,我们了解到对于一般神经网络,它们的基本组成结构分为输入层、隐藏层和输出层三个部分,隐藏层分布的各个神经元彼此独立,他们各自从输入层接受输入并进行计算,汇总之后再传送至输出层;还有反向传导算法的实现过程。
理论上,参数越多的模型复杂度越高,同时也能够完成更加复杂的学习任务,但是与此同时参数过多造成许多不足。通常,一般神经网络会面临参数剧增的问题,比如神经网络的输入为一个 [255, 255, 3] 的矩阵,完全展开后即为 172,125 维的向量,假设隐藏层有 1,000 个神经元,那么仅仅从输入层到第一层隐藏层参数的个数就达到了 255×255×3×1000=172,125,000 个!是不是有点恐怖?如果再向神经网络添加几个隐藏层,参数数量上升的速度会非常快,从而在计算上将变得十分耗时(近年来深度学习大热,与计算机计算能力大幅提升的背景离不开),并且参数数量过多还容易导致模型的过拟合。而 CNN 通过参数共享(shared weights)、下采样(sub-sampling)等手段能够较好地克服了一般神经网络中参数剧增的缺陷。
1. CNN 结构的解释
1.1 卷积、池化、全连接
在理解 CNN 的结构之前,有必要了解几个基本的概念:卷积(Convolution)、池化(Pooling)和全连接(Fully-Connected),将这三种不同的层按照一定的结构连接起来便组成了卷积神经网络的基本架构。
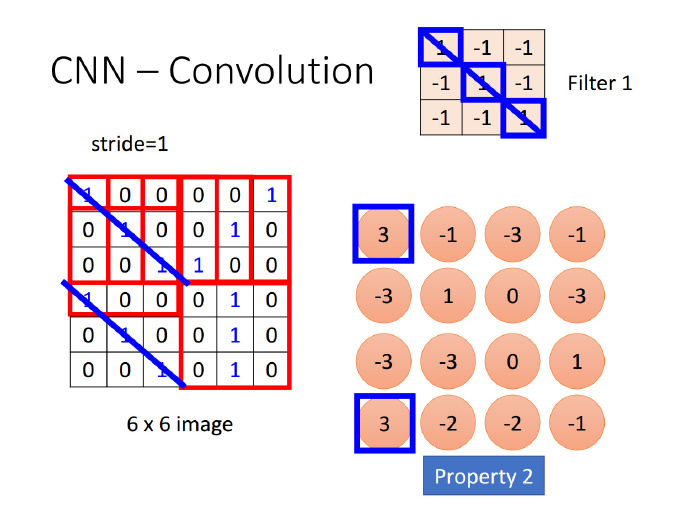
卷积
“自然图像有其固有特性,也就是说,图像的一部分的统计特性与其他部分是一样的”,也就是说图像或者是向量化后的文字同样具备一定的统计特性,即同样也可以进行特征提取、组合。在 CNN 中,卷积运算便是这么一个过程,不同于拥有显示特征的数据,CNN 对数据的特征提取是通过 filter 来进行的,每个 filter 都有着采集不同的特征的任务,因此 filter 中参数的大小是不相同的。

以识别图像中的小鸟为例,有的 filter 可能专门找像鸟嘴的部分,有的则专门找寻找像鸟的尾巴的部分,并且 feature map 会共享(sharing)来自 filter 的参数。
池化
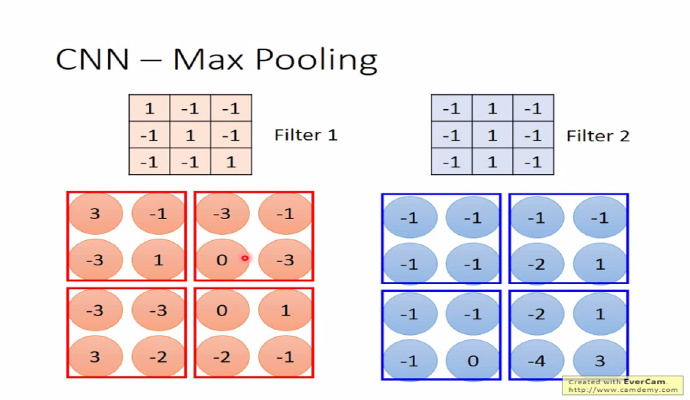
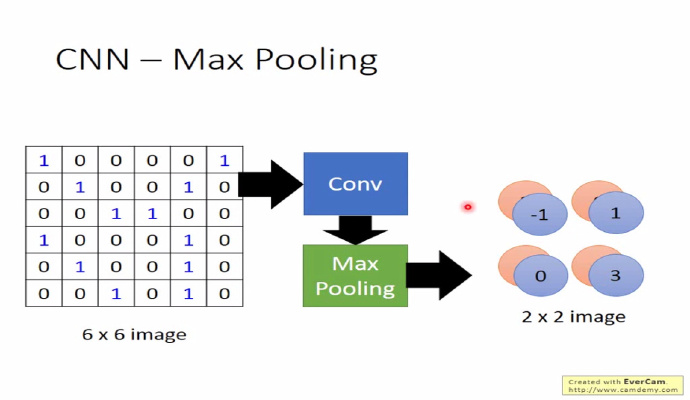
池化的目的是为了减轻计算量的压力,池化还有一个作用,它能够使模型具备识别平移、转换、缩放图片的功能@杨培文。比如对于一个 32×32 的图像,如果经过 100 个 5×5 filter 卷积提取得到 100 个(32-5+1)×(32-5+1)=784维的卷积特征,那么对于每个输入都有 78,400 维度的卷积特征向量,这个给计算带来了巨大的压力。 为了解决这个问题,池化的方法比较简单,可以理解它是一个采样的过程,对 filter 过滤出来的 feature map,我们可以将它分成几个小块,然后对每个小块采取取最大(max pooling)或取平均(average pooling)的操作,从而达到降维的目的。
然后 CNN 反复重复 Conv->Pooling 的这个过程,最后展开(flatten)连接到全连接层。这时参数个数便能够下降到可以接受的范围之内。
1.2 卷积层、池化层大小的计算
无论是卷积到池化还是池化到卷积,两个过程的参数个数计算其实区别不大
- 输入:$W_1, H_1, D_1$
四个超参数(hyper parameters)
- 滤波器(filter)的个数: $K$
- 滤波器的大小: $F$
- 步长(stride): $S$
- 零填充(zero padding)的个数: $P$
输出: $W_2, H_2, D_2$
- $W_2 = (W_1 - F + 2P)/S + 1 $
- $H_2 = (H_1 - F + 2P)/S + 1$
- $D_2 = K$
如果输入层有$n$个 channel,滤波器(filter)会考虑到 channel 的深度,那么滤波器的结构一般也是($··n$)的结构;filter 的个数决定了卷积层的深度$D$和 feature map 的个数
如下图,如果输入的图像有 RGB 3 个 channel,相应 filter 的结构也为 $··3$
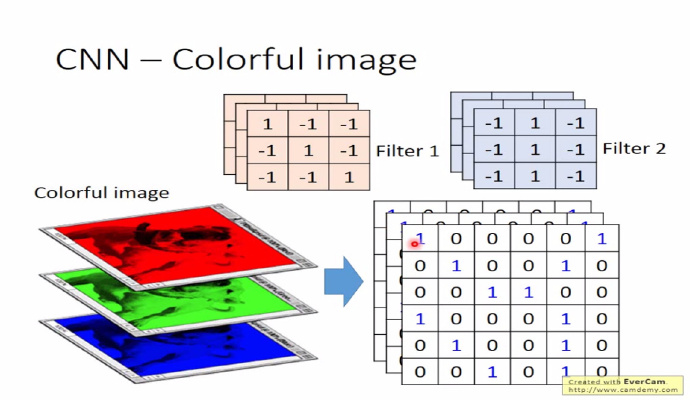

零填充(zero padding)个数有助于适应 filter 和控制输出单元的大小
1.3 例子
举个例子,赢得 2012 年 ImageNet 的 Krizhevsky et al. CNN 架构中接受的是 [227×227×3] 大小的图片(原文中是说224×224×3,但这样计算得到的卷积层大小不是一个整数,应该是作者使用了零填充但是却忘了在文中提及),一共有 (K = 96) 个大小为 [11×11×3] 的滤波器,F = 11,步长 S = 4, 那么卷积层计算 $(227 - 11+0)/4 + 1 = 55$,卷积层的大小便为 [55×55×96]。
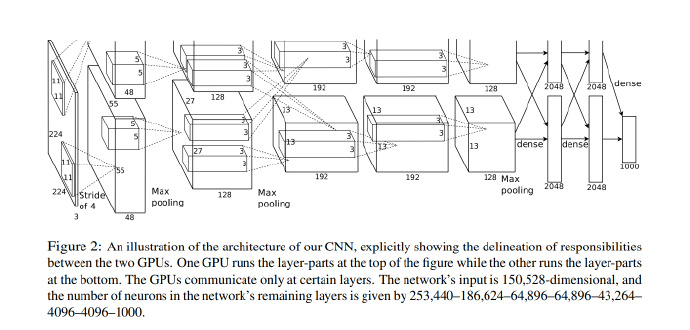
2. 经典的 LeNet-5
若要提起 CNN,就不得不提起 Yann LeCun 用 CNN 进行手写数字识别任务的论文,LeCun 这篇经典论文的插图在各种文章中被引用了无数遍,相信你也不是第一次在这里看到这幅图片
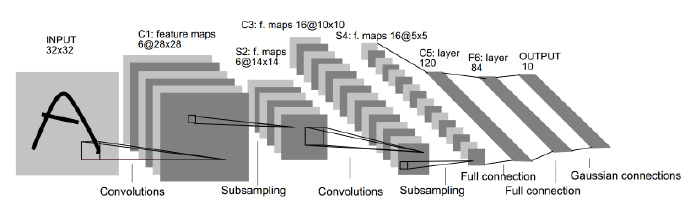
如上图所示,不包括输入层(Input layer),LeNet-5 网络一共有 7 层,分别是 3 个 卷积层(Convolution layer),2 个采样层(Subsampling layer),1 个全连接层(Fully-Connect layer)和 1 个输出层(Output layer)。
LeNet-5 的输入层是 32×32 的手写数字图像的像素矩阵,输出层是长度为 10 的向量,分别对应 10 个数字相应的概率。$Cx$ 表示卷积层,$Sx$ 表示采样层,$Fx$ 表示全连接层($x$ 表示层的索引)。Lenet-5 经过两轮的卷积(Convolution)、采样(Subsampling)重复操作,32×32 的输入被整合为 16 个 10×10 的矩阵,最后经过两个全连接层到达输出层。
C1
C1 卷积层有 6 个 feature map,这 6 个 feature map 分别由 6 个 5×5 的 filter 过滤得来。算上偏置项(bias),从输入层到卷积层中间有(5×5+1)×6=156 个可以训练的参数(trainable parameter)(对比一般神经网络,参数数量根本不是一个数量级)和 (28×28×6)×(5×5+1)=122,304 个连接。
S2->C3
S2 采样层共有 12 个参数和 5880 个连接。

C3 卷积层有 16 个 feature map,上面讲过有多少个 filter 就有多少个 feature map。显然,S2 采样层到 C3 卷积层之间有 16 个 filter,与 C1 卷积层一样,每个 filter 的大小为 5×5。然而,C3 卷积层的参数个数计算稍微有点绕,LeCun 在原文中的解释如下图:

原文大意是:前 6 个 feature map 从采样层相邻的 3 个子集获得输入,接下来的 6 个 feature map 又从采样层相邻的 4 个子集获得输入,剩余的 feature map 也依照这种办法生成。为什么要采用这种方法来生成 feature map 呢?LeCun 解释有两个方面的原因,首先这种不完全的连接(non-complete connection)能够保证连接数能被控制在一定的范围之内,再者便是它能够强行打破网络的对称性(symmetry in the network),不同的 feature map 能较好地提取不同的特征。
通过下面这幅图以前 6 个 feature map 从采样层相邻的 3 个子集获得输入为例,只不过这里单个生成 feature map 的 filter 是由三个 5×5 的矩阵联合组成的。
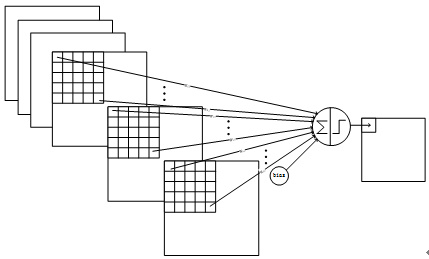
从 S2 到 C3 总共有 1,516(456+606+303+151) 个可训练的参数,每个 filter 连接的都是 10×10 的 feature map,那么全连接数即为 151,600 个。
S4->C5
S4 是有 16 个 5×5 大小feature map 组成的采样层,由上面的算法,一共有 32 个可训练的参数和 2,000 个连接。
C5 卷积层拥有 120 个 feature map,因为 C5 卷积层的 feature map 是 1×1 的,所以 S4 与 C5 之间的连接是全连接,将 S4 铺平展开为一个 400(5×5×16)×1 的矩阵,则可训练参数的个数为 400×120+120=48,120 个。
终于到 F6 全连接层了,全连接层有 84 个单元,与 C5 卷积层 fully connected 之后,它们之间一共有 10,164 个参数。
以手写数字识别为例,CNN 的输出有十个单元,对应 F6 ,不难得出全连接层到输出层有840个连接,840个可训练的参数。
以上就是 LeNet-5 的卷积神经网络的完整结构解释,网络中共计 60,840 个训练参数,340,908 个连接,参数和连接数统计表格总结如下:
| 卷积-采样 | 训练参数 | 连接数 |
|---|---|---|
| input->C1 | 156 | 1,122,304 |
| C1->S2 | 12 | 5,880 |
| S2->C3 | 1,516 | 151,600 |
| C3->S4 | 32 | 2,000 |
| S4->C5 | 48,120 | 48,120 |
| C5->F6 | 10,164 | 10,164 |
| F6->output | 840 | 840 |
| 总计 | 60,840 | 340,908 |
3. CNN 是如何学习的?
在接触 CNN 的过程中,似乎感觉其解释性不够强,给人一种“黑盒”的印象。简单讲讲 CNN 是如何进行学习的?以数字识别为例,专门寻找数字 8 弯弯曲曲特征的 filter 过滤生成了 feature map,把 feature map 的每一个元素相加得到 $a^k$,表示 filter 被刺激的程度,CNN 的任务便是寻找一张能够使 $a^k$ 最大的 image x。
4. CNN 在文本分类中的表现
CNN 非常强大,在文本、图像分类上尤为突出,即使没有做任何数据预处理的操作,简单的模型也能得到很好的效果。
…..Despite little tuning of hyperparameters, this simple model achieves excellent results on multiple benchmarks……
简单说一下 Kim, Y. (2014). 的这篇文章,作者在实验时直接用了 Mikolov 从 Google News 1000 亿个单词中预训练好的词向量,通过 CNN 来做句子层面的分类任务,并得到了非常理想的结果。思路如下:假设词向量 $x_i$ 为 $k$ 维向量,(k 等于句子的最大长度,这样才能保证输入的矩阵维度一致),$x_i$ 对应着句子中的第 $i$ 个词,如此一来,一个长度为 $n$ 的句子便可以表示为 $n×k$ 的矩阵,这么一来句子便可以进行向量计算了!(不得不佩服 Mikolov,他是怎么想到 word2vec 这个办法的)

接下来的步骤便是依葫芦画瓢了,卷积提取特征,从 feature map 中选择一个最大值,进入全连接层,最后得到输出。实验结果如下,CNN 在 7 个语料库上有 4 个的准确率超过了传统方法。

5. Summary
如何理解 CNN?从人的经验角度来看,正如我们人识别动物,人们不会把动物仔仔细细看个遍才做出判断,而是看到小鸟有尖尖的嘴巴、羽毛、流线型的身体等等几个特征就能够分辨是不是小鸟。卷积神经网络的工作原理也类似,神经元不会像一般神经网络一样去傻傻地去遍历整张图片来提取特征,而是只需要看一小部分就行了,每个神经元都有自己独特的任务,如下图所示,神经元主要的任务是识别小鸟的嘴巴。
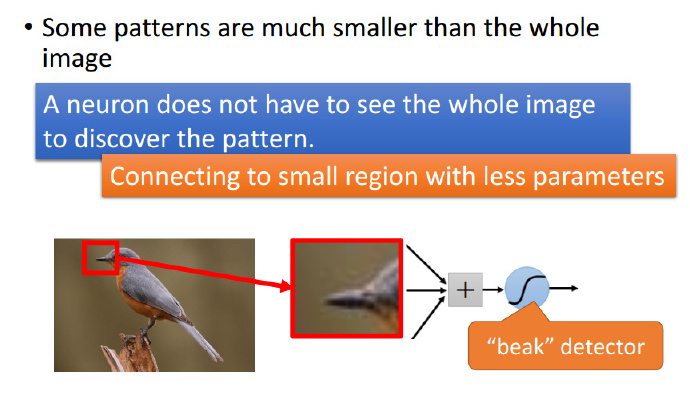
有人可能会问,如果小鸟的嘴巴没有在图片中央而是在右上角,是不是又需要一个专门识别右上角小鸟嘴巴的神经元呢?答案是否,相同特征可能会出现在图像中不同位置,在 CNN 中,这些发现相同特征的神经元彼此之间是共享参数的,实际上它们做的是同一件事情。
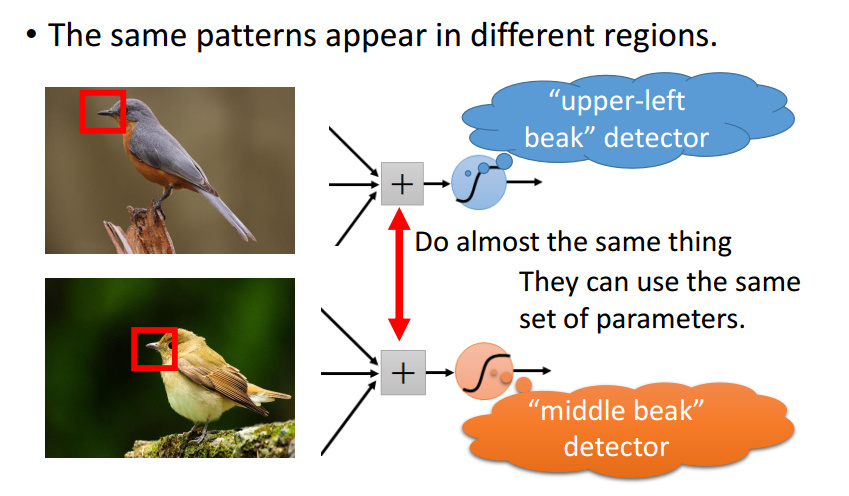
随着 CNN 层数的叠加,越往后面提取的特征越发抽象难以理解,还有如果特征太多了怎么办?那我们就取一小部分就好了。

池化的直观理解:去除图片的一部分有时候并不会影响对整个图片的理解。

在 CNN 中防止模型出现过拟合一般有 data augmentation 和 dropout 两种手段,前者是人工地增加数据量,后者是随机地让某些神经元失效,以达到减少参数量的效果。
事实上,CNN 与深度学习、AI 总是形影不离,因此在我的印象里 CNN 一定是那种非常复杂高深的机器学习方法;另外,笔者第一次接触 CNN 是在学习 fast.ai(只知道讲课的老师非常认真,现在不知道怎么样了)提供的课程,当时因为文档不完善再加上自己又是一个不折不扣菜鸟,光配置 aws 就吃了不少苦头,第一节“猫狗大战”的任务都没有完成就放弃了,于是便形成了认为 CNN 一定非常难以理解的感觉,甚至于有点恐惧。但实际上,“柳暗花明又一村”,CNN 与普通全连接的神经网络区别不大,唯一的区别是 CNN 仅仅只连接到了输入的局部,并且众多的神经元彼此之间共享参数。
PS:如果有时间,接下来我会写一写如何用 CNN 实现文本分类的文章。
推荐阅读
- http://cs231n.github.io/convolutional-networks/
- http://scs.ryerson.ca/~aharley/vis/conv/
- http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/CNN%20(v2).pdf.pdf)
- http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
- http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
- http://www.aclweb.org/anthology/D14-1181
- https://adeshpande3.github.io/adeshpande3.github.io/A-Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks/
- https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf
- ufldl:卷积特征提取
- CNN资源合集:来自@爱可可老师的微博

