前两篇笔记主要记录了在线性可分、线性不可分和非线性可分三种情形下,如何将支持向量机的原始优化问题转化为只有一个参数的对偶问题,对偶问题的求解实现没有记录,这篇笔记讲到的序列最小最优算法(SMO)就是一种高效实现支持向量机学习的算法。
由上一篇笔记,凸二次规划的对偶问题
1. SMO 算法基本思路
不同于之前解决二次规划问题所采取的手段,SMO 选择在每一步解决一个最小可能的优化问题,通过求解子问题来逼近原始问题,这可以大大提高整个算法的计算速度,是一种启发式的方法。SMO 与提升树中的前向分步算法或者ALS(交替最小二乘法)的思路殊途同归,它们都是通过不断解决小问题来逼近最优解。
SMO 的优势:
- can be done analytically
- 不需要额外的矩阵存储空间
- SMO = analytic method + heuristic(启发式)
由上述对偶问题,假设先固定除$\alpha_1,\alpha_2$之外的所有其他变量,于是对偶问题的子问题可以等价写为
由对偶问题的约束条件$\sum_{i=1}^{N}\alpha_iy_i=0$,得:
左右两边同乘一个$y_1$,得:
因为${y_1}^2$恒为1,显然:
我们将$\alpha_1$代入子问题,从而消去$\alpha_1$。也就是说,对偶问题两个变量中只有一个是自由变量,实际上是单变量的优化问题,这样问题就更加简化了!
2. 两个变量的凸二次规划问题求解
通过变换,我们将子问题变成了只有$\alpha_2$的单变量优化问题。如何求解$\alpha_2$?考虑两种情形
(1)考虑$y_1*y_2$的两种不同情形
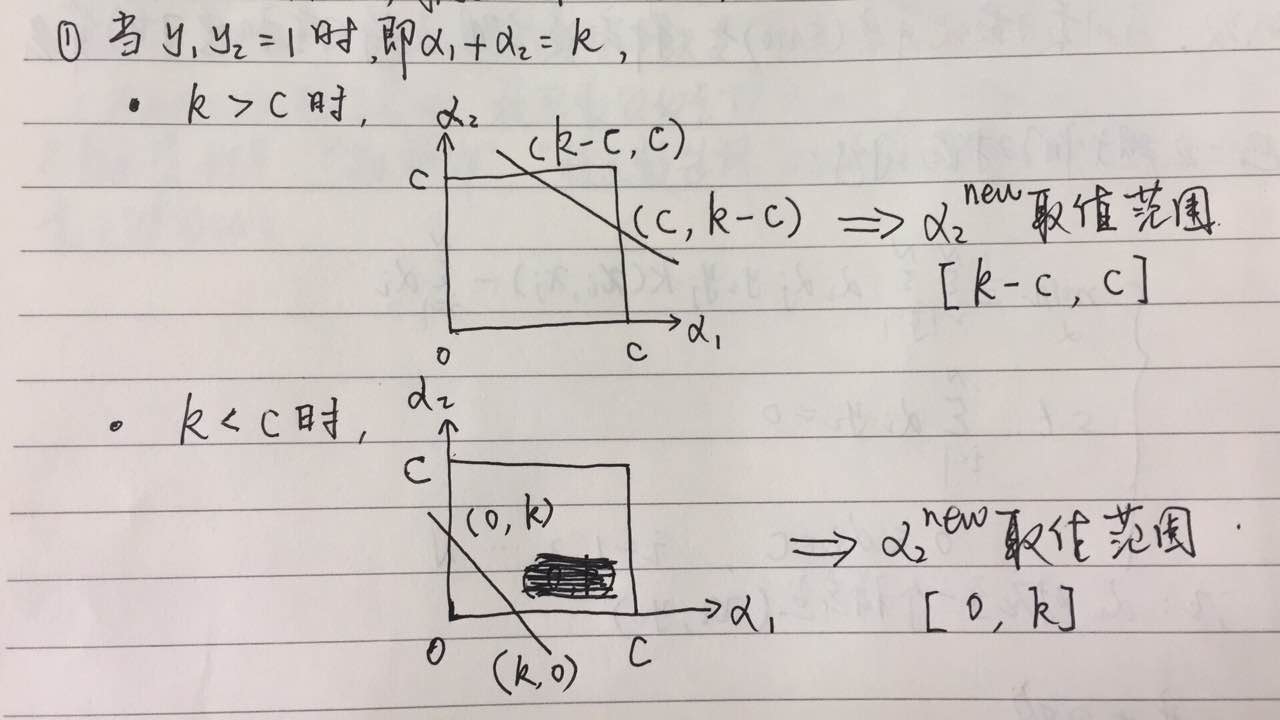
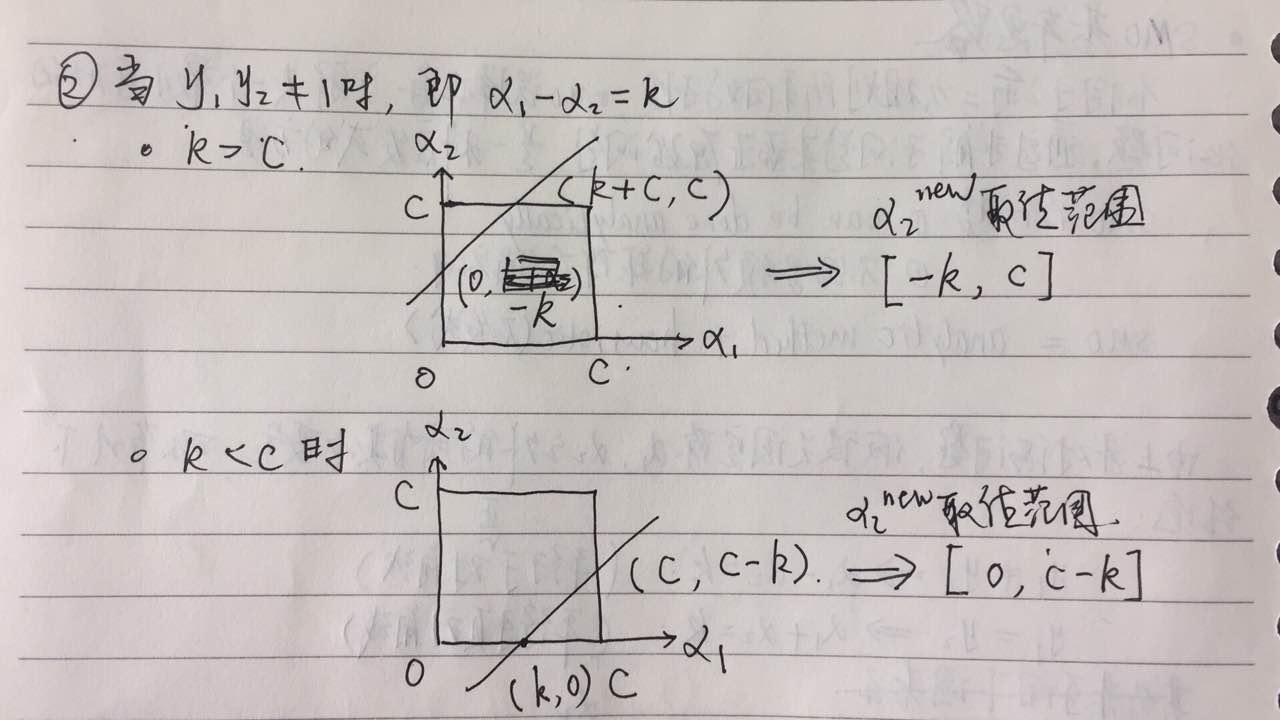
设$L$与$H$是在对角线段端点的上界和下界,由上图所示,要得到$\alpha_2$的准确取值范围,上界我们取两个最大值的最小值,下界取两个最小值的最大值即可。由
由
(2)不考虑约束条件求$\alpha_{2}^{new,unc}$
首先,$\alpha2$的约束条件很多,为了避免求解太繁,我们先不考虑上面两个条件的约束得到$\alpha{2}^{new,unc}$(unc,即uncertain,不确定)的最优解,然后再求约束条件下的最优解$\alpha_{2}^{new}$。
解:
设
令误差
记
故子问题的目标函数可以写为
因为
所以
代入目标函数,得
这样目标函数只有一个未知参数了!针对单变量的凸二次规划问题,这太简单了。
(3)单变量的凸二次规划问题
对$\alpha_2$求导并令其为零
得
将$\alpha_1y_1+\alpha_2y_2=k$代入,得
以下是详细的求解过程:

我们令$\eta=K{11}+K{22}-2K_{12}$,得
再考虑求解约束条件后的$\alpha_{2}^{new}$
(4)考虑求解约束条件$\alpha_{2}^{new}$
因为
所以
于是,我们经过上述的推导,终于就得到了对偶问题子问题的解$(\alpha{1}^{new},\alpha{2}^{new})$。
(5)重新计算$b$和差值$E_i$
在每次完成两个变量的优化后,我们还需要将$\alpha_2^{new}$与$\alpha_2^{old}$比较,如果变化的程度不大,则要重新计算阈值$b$和差值$E_i$


3. 基于 Python 实现 SMO 的代码分析
这是基于 Python 实现 SVM 中的 SMO 算法,来自于《机器学习实战》,代码很容易读,基本可以与上文的公式推导完全对应,所以不太理解的地方,还是把 SMO 推导过程的来龙去脉先捋一捋吧!
1 | from numpy import * |
推荐阅读
- 《机器学习》.周志华
- 《统计学习方法》.李航
- 《机器学习实战》.Peter Harrington
- https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-98-14.pdf

