决策树(decision tree)是一类常见的机器学习(分类)方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策树对新数据进行分析。
- 决策树的模型与学习
- 特征选择
- 决策树的生成
1. 决策树的模型与学习
1.1 简单的例子:选西瓜的一棵决策树
一般,一颗决策树包含一个根节点(node),若干个内部结点(internal node)和若干个叶节点(leaf node);叶节点对应于决策结果,其他每个结点对应于一个属性测试;每个结点包含的样本的集合根据属性测试的结果被划分到子节点中。
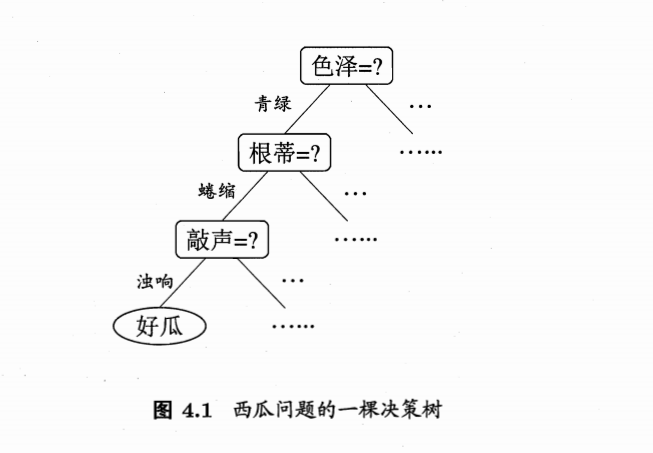
在沿着决策树从上到下的遍历过程中,在每个结点都有一个测试。对每个结点上问题的不同测试输出导致不同的分支,最后会达到一个叶子结点。这一过程就是利用决策树进行分类的过程,利用若干个变量来判断属性的类别。

1.2 决策树模型
决策树(decision tree)是一类常见的机器学习(分类)方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策树对新数据进行分析。
决策树本质上是从训练数据集中归纳出一组分类规则,决策树学习通常包括三个步骤:特征选择、决策树生成和决策树修剪。
1.3 决策树和归纳算法
- 决策树技术发现数据模式和规则的核心是归纳算法
- 归纳是从特殊到一般的过程
- 归纳推理从若干个事实中表征出的特征、特性和属性中,通过比较、总结、概括而得出一个规律性的结论
- 归纳推理视图从对象的一部分或整体的特定的观察中获得一个完备且正确的描述,即从特殊事实到普遍性规律的结论
- 归纳对于认识的发展和完善具有重要的意义。人类知识的增长主要来源于归纳学习,机器也是如此。
从特殊的训练样例中归纳出一般函数是机器学习的核心问题,从训练样例中进行学习的过程:
1 | 1. 训练集D={(x1,y1), (x2,y2),…,(xn,yn)},属性集A={a1,a2,…,av} |
1.4 选择方法
使训练值与假设值预测出的值之间的误差平方和Err最小
1.5 决策树算法
决策树相关的重要算法包括:ID3,C4.5,CART
决策树算法的发展历程
Hunt,Marin和Stone 于1966年研制的CLS学习系统,用于学习单个概念。
1979年, J.R. Quinlan 给出ID3算法,并在1983年和1986年对ID3进行了总结和简化,使其成为决策树学习算法的典型。
Schlimmer 和Fisher于1986年对ID3进行改造,在每个可能的决策树节点创建缓冲区,使决策树可以递增式生成,得到ID4算法。
1993年,Quinlan 进一步发展了ID3算法,改进成C4.5算法。
另一类决策树算法为CART,与C4.5不同的是,CART的决策树由二元逻辑问题生成,每个树节 点只有两个分枝,分别包括学习实例的正例与反例。

2. 特征选择
决策的关键在于如何选择最优划分属性一般而言,随着划分过程不断进行,决策树分支结点所包含的样本尽可能属于同一类别,即“纯度”越来越高。通常特征选择的准则是信息增益(information gain)或信息增益比(gain ratio)。
2.1 信息熵(Entropy)
三十而立,四十而不惑,五十知天命…人生,就是一次熵不断变小的过程。
香农1948年提出信息论理论,在信息论和概率统计中,熵(entropy)是表示随机变量不确定性的度量,用来度量样本集合纯度最常用的一些指标。样本集合D中第k类样本所占比例为pk(k=1,2,…,|y|),则D的信息熵定义为:
熵越大,随机变量的不确定性越大。当D服从0,1分布时,熵与不确定性程度的关系:
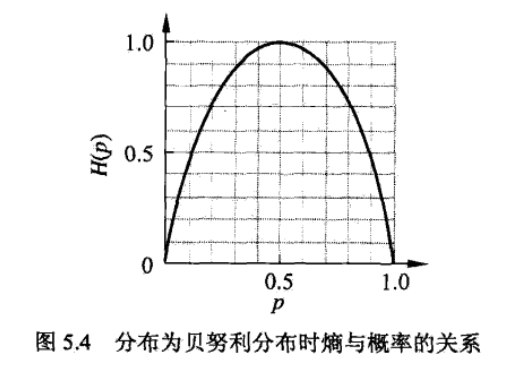
如图,当p为0或1时,熵值最小,随机变量完全没有不确定性,当p=0.5时,熵值达到最大值,随机变量的不确定性最大。
2.2 信息增益(Information gain)
假定离散属性a有V个可能的取值{a1,a2,…,aV},使用a对样本集进行划分,则会产生V个分支结点,其中第v个分支结点包含了D中所有在属性a上取值为av的样本,记为Dv,于是可以计算出属性a对样本集D进行划分所获得的信息增益(information gain):
信息增益表示得知属性a的信息而使得D的信息不确定性减少的程度,决策树学习中的信息增益等价于训练数据集中划分属性与类别的互信息(mutual information)。
信息增益表示属性a使得数据集D的分类不确定性减少的程度
对于数据集D而言,信息增益依赖于特征,不同的特征往往具有不同的信息增益
信息增益大的特征具有更强的分类能力
信息增益指标可能会出现泛化能力不佳的情形,假如用编号作为划分指标,那么信息增益将达到最大值,显然,这样的决策树不能对新样本进行预测
2.3 信息增益率(Gain ratio)
著名的C4.5决策树算法不直接使用信息增益,而是使用信息增益率(gain ratio)来选择最优划分属性,增益率定义为:
IV(a)称为a属性的“固有值”(intrinsic value),所以一般增益率准则对数目较少的属性有所偏好。如果av属性的数目越大,IV(a)相应也会变大,所以比较其增益就没有太大优势。举个例子,如果需要你选择一个特征来划分人群,身份证号码是一个完美的选择,但是我们并不能在实际中应用这个特征。选择信息增益率来做特征选择就是为了避免出现这种状况,我们不仅仅要考量特征对数据的划分能力,而且还需要考察特征本省的信息熵。
2.4 基尼指数(Gini index)
CART决策树使用基尼指数来选择划分属性,数据集D的纯度可以用基尼值来度量:
Gini(D)反映了从数据集中随机抽取两个样本,其类别标记不一致的概率,因此Gini(D)越小,数据集D的纯度越高
于是,属性集合A中,选择使得划分后基尼指数最小的属性作为最优划分属性
3. 决策树的生成
ID3算法
ID3算法-流程
ID3算法-小结
C4.5算法
3.1 决策树ID3算法
ID3算法是一种经典的决策树学习算法,由Quinlan与1979年提出。
ID3算法主要针对属性选择问题。是决策树学习方法中最具影响和最为典型的算法。
ID3采用信息增益度选择测试属性。
当获取信息时,将不确定的内容转为确定的内容,因此信息伴随不确定性。
在决策树分类中,假定D是训练样本集合,|D|是训练样本数,离散属性a有V个可能的取值{a1,a2,…,aV},使用a对样本集进行划分,则会产生V个分支结点,其中第v个分支结点包含了D中所有在属性a上取值为av的样本,记为Dv,于是可以计算出属性a对样本集D进行划分所获得的信息增益(information gain):
信息增益表示得知属性a的信息而使得D的信息不确定性减少的程度。经验条件熵H(D|A)表示在特征A给定的条件下对数据集D进行分类的不确定性,它们的差,即信息增益。
3.2 决策树ID3算法-流程
1 |
|
3.3 ID3算法-小结
ID3算法的基本思想是,以信息熵为度量,用于决策树结点的属性选择,每次优先选取信息量最多的属性,构建一棵熵值下降最快的决策树,到叶节点处的熵值为0
3.4 决策树C4.5生成算法
ID3算法只有树的生成,所以该算法容易生成的树很容易产生过拟合,从而泛化能力不佳。C4.5的算法过程与ID3类似,只是属性选择的指标换成了信息增益比。
4. Python 实现代码分析
1 | from math import log |
majorityCnt(classList)函数使用分类名称的列表然后创建值为classList中唯一值的数据字典,字典对象存储了classList中每个类标签出现的频率,最后利用operator操作键值排序字典,并返回出现次数最多的分类名称。
1 | def majorityCnt(classList): |
推荐阅读
周志华.机器学习[M].2016年1月第一版.清华大学出版社.2016
李航.统计学习方法[M].2012年3月第1版.清华大学出版社.2015
继续阅读机器学习算法系列笔记!

